面试
leetcode
跳槽
生活
数字化
CVE-2022-27925
cocos2dx-lua
图卷积神经网络
insert into
程序员人生
Pyinstaller
多模态
XAML
PC
渲染管线
网赚项目
BH1750
定时同步
printf
天气App
Hudi
2024/4/11 15:38:36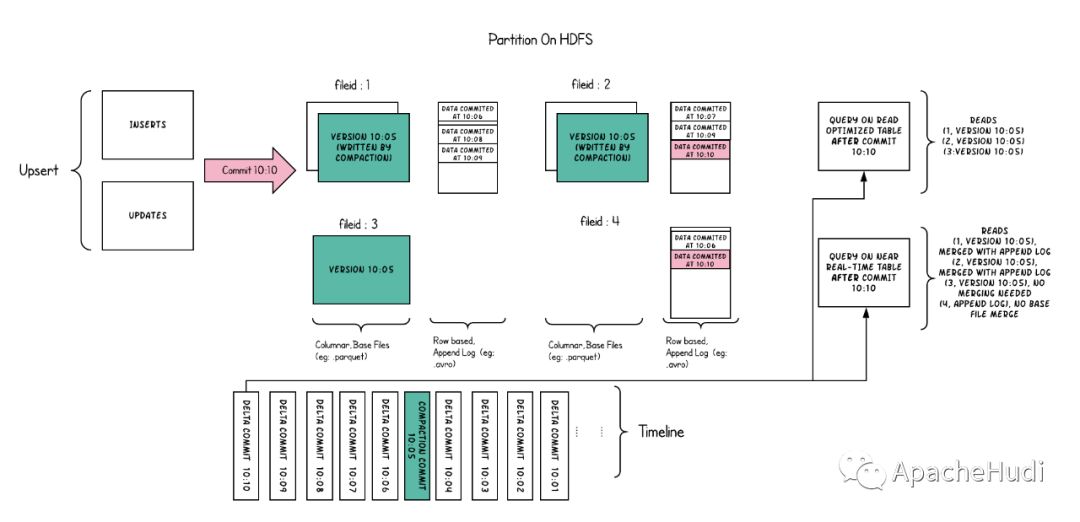

Hudi Java Client总结|读取Hive写Hudi代码示例
前言
Hudi除了支持Spark、Fink写Hudi外,还支持Java客户端。本文总结Hudi Java Client如何使用,主要为代码示例,可以实现读取Hive表写Hudi表。当然也支持读取其他数据源,比如mysql,实现读取mysql的历史数据和增量数据写…
#Apache Hudi初探(五)(与spark的结合)
背景
目前hudi的与spark的集合还是基于spark datasource V1来的,这一点可以查看hudi的source实现就可以知道:
class DefaultSource extends RelationProviderwith SchemaRelationProviderwith CreatableRelationProviderwith DataSourceRegisterwith StreamSinkPr…
Hudi-简介和编译安装
简介
简介
Apache Hudi(Hadoop Upserts Delete and Incremental)是下一代流数据湖平台。Apache Hudi将核心仓库和数据库功能直接引入数据湖。Hudi提供了表、事务、高效的upserts/delete、高级索引、流摄取服务、数据集群/压缩优化和并发,同…

Hudi集成Flink-写入方式
文章目录一、CDC 入湖1.1、[开启binlog](https://blog.csdn.net/wuxintdrh/article/details/130142601)1.2、创建测试表1.2.1、创建mysql表1.2.2、将 binlog 日志 写入 kafka1、使用 mysql-cdc 监听 binlog2、kafka 作为 sink表3、写入sink 表1.2.3、将 kakfa 数据写入hudi1、k…
Apache Hudi初探(五)(与spark的结合)
背景
目前hudi的与spark的集合还是基于spark datasource V1来的,这一点可以查看hudi的source实现就可以知道:
class DefaultSource extends RelationProviderwith SchemaRelationProviderwith CreatableRelationProviderwith DataSourceRegisterwith StreamSinkPr…
Spark集成hudi创建表报错
环境描述:
hudi版本:0.13.1
spark版本:3.3.2
Hive版本:3.1.3
Hadoop版本:3.3.4 问题1:
描述:按照官方文档运行spark-sql创建spark的hudi表报错
建表语句:
CREATE TABLE stg.spark_mor_test_01
(uuid string,name string,age int,ts …

Apache Hudi初探(二)(与flink的结合)--flink写hudi的操作(JobManager端的提交操作)
背景
在Apache Hudi初探(一)(与flink的结合)中,我们提到了Pipelines.hoodieStreamWrite 写hudi文件,这个操作真正写hudi是在Pipelines.hoodieStreamWrite方法下的transform(opName("stream_write", conf), TypeInformation.of(Object.class), operatorFa…
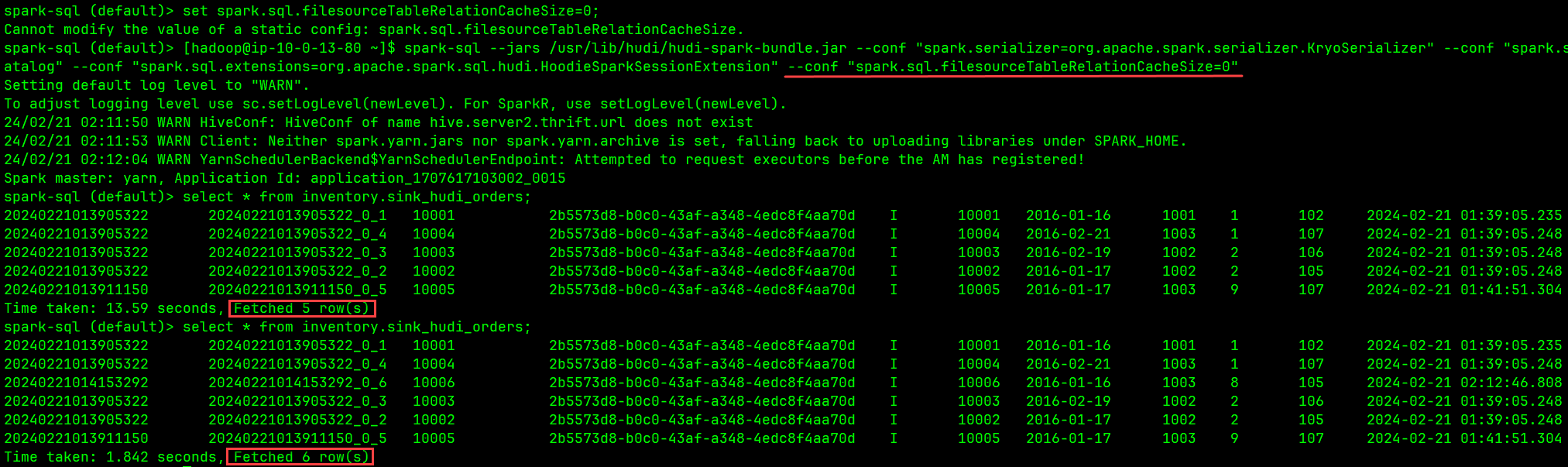
问题:Spark SQL 读不到 Flink 写入 Hudi 表的新数据,打开新 Session 才可见
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
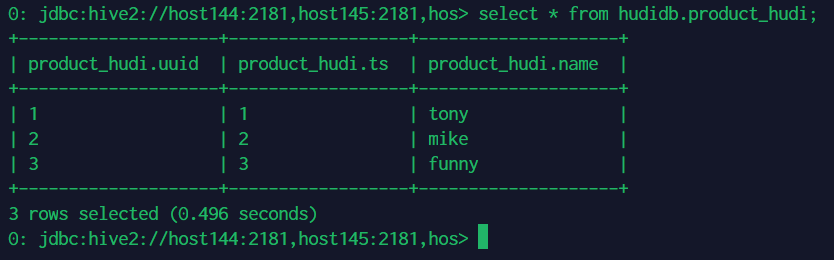
【大数据】Hudi HMS Catalog 完全使用指南
Hudi HMS Catalog 完全使用指南 1.Hudi HMS Catalog 基本介绍2.在 Flink 中写入数据3.在 Flink SQL 中查看数据4.在 Spark 中查看数据5.在 Hive 中查看数据 1.Hudi HMS Catalog 基本介绍
功能亮点:当 Flink 和 Spark 同时接入 Hive Metastore(HMS&#…
Hudi0.14.0最新编译(修订版)
1 编译环境 Java1.8maven3.9.3hadoop3.3.4hive3.1.3spark3.2.1flink1.16.0hudi0.14.02 hudi准备
2.1 源码
$ git clone https://github.com/apache/hudi.git
$ cd hudi
$ git checkout release-0.14.02.2 修改pom文件
2.2.1 新增repository加速依赖下载
<
CDC 整合方案:MySQL > Flink CDC > Kafka > Hudi
继上一篇 《CDC 整合方案:MySQL > Kafka Connect + Schema Registry + Avro > Kafka > Hudi》 讨论了一种典型的 CDC 集成方案后,本文,我们改用 Flink CDC 完成同样的 CDC 数据入湖任务。与上一个方案有所不同的是:借助现有的 Flink 环境,我们可以直接使用 Flink CDC 从…
Scala操作hudi
文章目录Scala操作hudi1、启动客户端2、配置信息3、 创建数据表4、插入数据5、查询数据6、更新数据7、增量查询8、时间点查询9、删除数据10、覆盖写入Scala操作hudi
1、启动客户端
//spark3.1
spark-shell \--packages org.apache.hudi:hudi-spark3.1.2-bundle_2.12:0.10.1,o…

CDC 整合方案:Flink 集成 Confluent Schema Registry 读取 Debezium 消息写入 Hudi
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
Hudi-源码-索引-bloom 索引
文章目录 前言问题原理TagLocation流程入口LookupIndexfindMatchingFilesForRecordKeysHoodieKeyLookupHandle 如何优化问题一 如何避免大量 IO问题二 如何减少计算 Hash问题三 使用什么结构优化比对结果如何初始化树查询 总结 前言
Hudi 系列文章在这个这里查看 https://gith…
Hudi 0.14.0 编译
1 编译环境 Java1.8maven3.9.3hadoop3.3.4hive3.1.3spark3.2.1flink1.16.0hudi0.14.02 hudi准备
2.1 源码
$ git clone https://github.com/apache/hudi.git
$ cd hudi
$ git checkout release-0.14.02.2 修改pom文件
2.2.1 新增repository加速依赖下载
<
Apache Iceberg最新最全面试题及详细参考答案(持续更新)
目录
1. 描述Apache Iceberg的架构设计和它的主要组件?
2. Iceberg如何处理数据的版本控制和时间旅行?
Hudi表类型和查询类型
官方参考
Table & Query Types
查询类型
快照查询(Snapshot Queries)
查询最新的数据。
增量查询(Incremental Queries)
查询指定时间范围内新增或修改的数据。
读优化查询(Read Optimized Queries…
Flink MySQL CDC connector 使用注意事项
注意事项 表要有主键 库名和表名不能有点号
是个 BUG,估计后续会修复。
表名不能有大写
也是个 BUG,估计后续会修复。
如果表名含有大写的字母,查询时日志可看到如下信息:
java.util.concurrent.ExecutionException: java.…
Hudi源码 | Insert源码分析总结(二)(WorkloadProfile)
前言
接上篇文章:Hudi源码 | Insert源码分析总结(一)(整体流程),继续进行Apache Hudi Insert源码分析总结,本文主要分析上文提到的WorkloadProfile
版本
Hudi 0.9.0
入口
入口在上篇文章中讲到的BaseJavaCommitAc…
flink实战--FlinkSQl实时写入hudi表元数据自动同步到hive
简介 为了实现hive, trino等组件实时查询hudi表的数据,可以通过使用Hive sync。在Flink操作表的时候,自动同步Hive的元数据。Hive metastore通过目录结构的来维护元数据,数据的更新是通过覆盖来保证事务。但是数据湖是通过追踪文件来管理元数据,一个目录中可以包含多个版本…
Apache Hudi初探(八)(与spark的结合)--非bulk_insert模式
背景
之前讨论的都是’hoodie.datasource.write.operation’:bulk_insert’的前提下,在这种模式下,是没有json文件的已形成如下的文件:
/dt1/.hoodie_partition_metadata
/dt1/2ffe3579-6ddb-4c5f-bf03-5c1b5dfce0a0-0_0-41263-0_202305282…
Apache Hudi初探(一)(与flink的结合)
背景
和Spark的使用方式不同,flink结合hudi的方式,是以SPI的方式,所以不需要像使用Spark的方式一样,Spark的方式如下:
spark.sql.extensionsorg.apache.spark.sql.hudi.HoodieSparkSessionExtension
spark.sql.catalog.spark_ca…
Hudi基础 -- DML
文章目录1.Insert data(插入数据)2.Query data(查询数据)3.Time Travel Query4.Update(更新操作)5.MergeInto(合并插入)6.Hard Deletes(硬删除)7.Insert Over…
Hudi系列20: Bucket索引
一. Bucket 索引概述
从 0.11 开始支持 默认的flink 流式 写入使用 state 存储索引信息: primary key 到 fileID 的映射关系。 当数据量比较大的时候, state的存储开销可能成为瓶颈, bucket 索引通过固定的 hash 策略, 将相同 key 的数据分配…
Hudi Spark SQL Call Procedures学习总结(一)(查询统计表文件信息)
前言
学习总结Hudi Spark SQL Call Procedures,Call Procedures在官网被称作存储过程(Stored Procedures),它是在Hudi 0.11.0版本由腾讯的ForwardXu大佬贡献的,它除了官网提到的几个Procedures外,还支持其…
CDC 整合方案:MySQL > Flink CDC + Schema Registry + Avro > Kafka > Hudi
本文是《CDC 整合方案:MySQL > Flink CDC > Kafka > Hudi》的增强版,在打通从源端数据库到 Hudi 表的完整链路的前提下,还额外做了如下两项工作: 引入 Confluent Schema Registry,有效控制和管理上下游的 Schema 变更 使用 Avro 格式替换 Json,搭配 Schema Registry,…
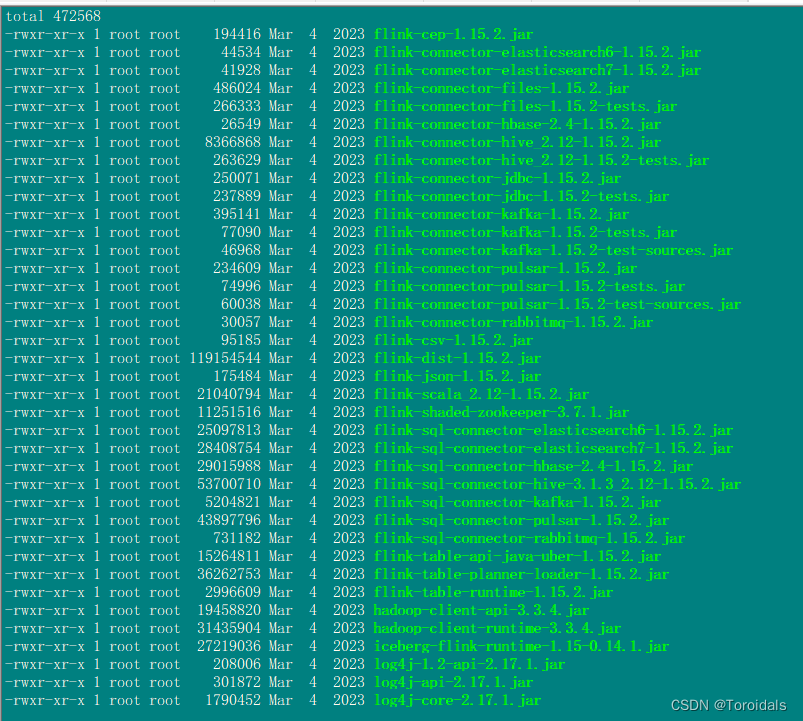
Flink、Spark、Hive集成Hudi
环境描述:
hudi版本:0.13.1
flink版本:flink-1.15.2
spark版本:3.3.2
Hive版本:3.1.3
Hadoop版本:3.3.4 一.Flink集成Hive
1.拷贝hadoop包到Flink lib目录
hadoop-client-api-3.3.4.jar
hadoop-client-runtime-3.3.4.jar
2.下载上传flink-hive的jar包
flink-co…

Apache Zeppelin 整合 Spark 和 Hudi
一 环境信息
1.1 组件版本
组件版本Spark3.2.3Hudi0.14.0Zeppelin0.11.0-SNAPSHOT
1.2 环境准备
Zeppelin 整合 Spark 参考:Apache Zeppelin 一文打尽Hudi0.14.0编译参考:Hudi0.14.0 最新编译
二 整合 Spark 和 Hudi
2.1 配置
%spark.confSPARK_H…

Flink 读取 Kafka 消息写入 Hudi 表无报错但没有写入任何记录的解决方法
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维…
Hudi0.14.0集成Spark3.2.3(Spark Shell方式)
1 启动
1.1 启动Spark Shell
# For Spark versions: 3.2 - 3.4
spark-shell --jars /path/to/jars/hudi-spark3.2-bundle_2.12-0.14.0.jar \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.sql.catalog.spark_catalog=org.apache.spar…
Hudi的Flink配置项(1)
名词
FallbackKeys
备选 keys,可理解为别名,当指定的 key 不存在是,则找备选 keys,在这里指配置项的名字。
相关源码
FlinkOptions
// https://github.com/apache/hudi/blob/master/hudi-flink-datasource/hudi-flink/src/ma…
hudi系列-基于cdc应用与优化
1. CDC是个好东西
曾经做数据同步受存储引擎和采集工具的限制,经常都是全量定时同步,亦或是以自增ID或时间作为增量的依据进行增量定时同步,无论是哪种,都存在数据延时较大、会重复同步不变的数据、浪费资源等问题。后来刚接触canal时还大感惊奇,基于mysql的binlog可以这…
hudi spark数据增删查改
1 使用spark-shell方式
# 启动命令行spark-shell \--conf spark.serializerorg.apache.spark.serializer.KryoSerializer \--conf spark.sql.catalog.spark_catalogorg.apache.spark.sql.hudi.catalog.HoodieCatalog \--conf spark.sql.extensionsorg.apache.spark.sql.hudi.H…
数据湖 Hudi 核心概念
文章目录 什么是 Hudi ?Hudi 是如何对数据进行管理的?Hudi 表结构Hudi 核心概念 什么是 Hudi ?
Hudi 是一个用于处理大数据湖的开源框架。
大数据湖是指一个大规模的、中心化的数据存储库,其中包含各种类型的数据,如结构化数据、半结构化…

记录几个Hudi Flink使用问题及解决方法
前言
如题,记录几个Hudi Flink使用问题,学习和使用Hudi Flink有一段时间,虽然目前用的还不够深入,但是目前也遇到了几个问题,现在将遇到的这几个问题以及解决方式记录一下
版本
Flink 1.15.4Hudi 0.13.0
流写
流写…

Hudi 系列-基础概念-索引机制
目录 前言问题作用减少开销怎么理解数据变更基础 类型全局索引FlinkSpark 总结 前言
Hudi 系列文章在这个这里查看 https://github.com/leosanqing/big-data-study
索引(Index)是 Hudi 最重要的特性之一,也是区别于之前传统数仓 Hive 的重要特点, 是实现 Time Travel, Update…
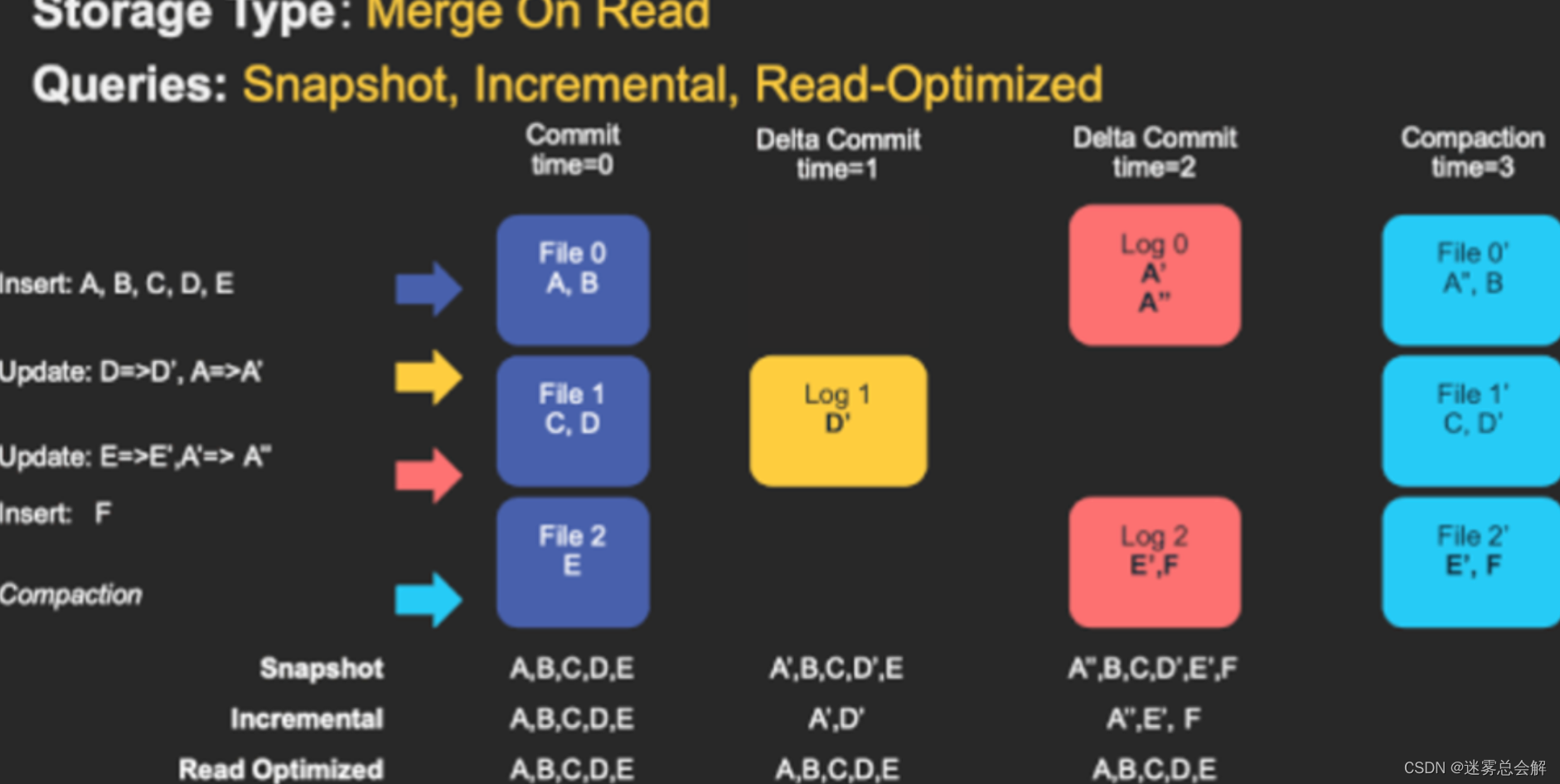
Hudi-基本概念(时间轴、文件布局、索引、表类型、查询类型、数据写、数据读、Compaction)
文章目录基本概念时间轴(TimeLine)文件布局(File Layout)Hudi表的文件结构Hudi存储的两个部分Hudi的具体文件说明索引(Index)原理索引选项全局索引与非全局索引索引的选择策略对事实表的延迟更新对事件表的去重对维度表的随机更删…

Flink CDC 提取记录变更时间作为事件时间和 Hudi 表的 precombine.field 以及1970-01-01 取值问题
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
尚硅谷大数据技术-数据湖Hudi视频教程-笔记01【概述、编译安装】
大数据新风口:Hudi数据湖(尚硅谷&Apache Hudi联合出品) B站直达:https://www.bilibili.com/video/BV1ue4y1i7na 尚硅谷数据湖Hudi视频教程百度网盘:https://pan.baidu.com/s/1NkPku5Pp-l0gfgoo63hR-Q?pwdyyds阿里…
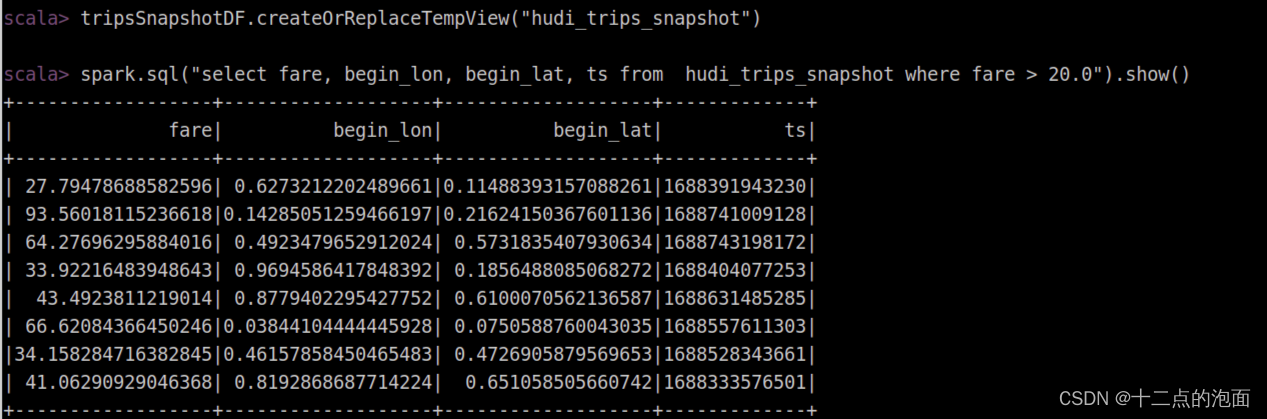
Hudi(22):Hudi集成Flink之常见问题汇总
目录
相关文章链接
问题一:存储一直看不到数据
问题二:数据有重复
问题三:Merge On Read 写只有 log 文件 相关文章链接 Hudi文章汇总
问题一:存储一直看不到数据
如果是 streaming 写,请确保开启 checkpoint&a…
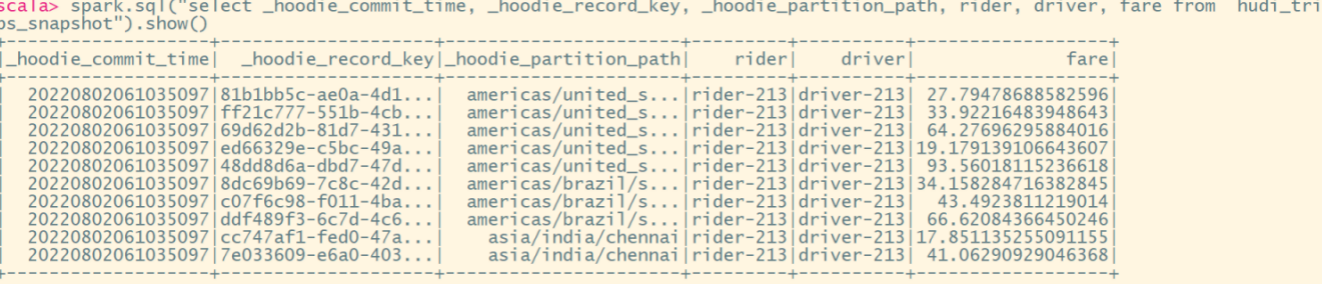
Hudi-集成Spark之spark-shell 方式
Hudi集成Spark之spark-shell 方式
启动 spark-shell
(1)启动命令
#针对Spark 3.2
spark-shell \--conf spark.serializerorg.apache.spark.serializer.KryoSerializer \--conf spark.sql.catalog.spark_catalogorg.apache.spark.sql.hudi.catalog.Hoo…

【LakeHouse】LakeHouse 架构指南
LakeHouse 架构指南 1.什么是数据湖,为什么需要数据湖2.数据湖、数据仓库和 LakeHouse 之间有什么区别3.数据湖的组件3.1 存储层 / 对象存储(AWS S3、Azure Blob Storage、Google Cloud Storage)3.2 数据湖文件格式(Apache Parque…
使用Flink MySQL cdc分别sink到ES、Kafka、Hudi
环境说明 [flink-1.13.1-bin-scala_2.11.tgz](https://archive.apache.org/dist/flink/flink-1.13.1/flink-1.13.1-bin-scala_2.11.tgz)[hadoop-2.7.3.tar.gz](https://archive.apache.org/dist/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz)[flink-cdc-connectors](https:…
Hudi的Index类型
Hudi 的索引是 hoodiekey 到文件组(File Group)或者文件 ID(File ID)的映射,hoodiekey 由 recordkey 和 partitionpath 两部分组成。
定义在文件 HoodieIndex.java 中。
分一下几种:
类型说明SIMPLE简单…

数据导入hudi报错,错将字段写到hdfs路径上
报错信息
Error trying to save partition metadata (this is okay, as long as atleast 1 of these succced), file:/qiche/hudi_table/冬天续航要打个八折的样子,能接受。高速相对市区还要耗电一些。不过这个车最主要是也就是在市区里面跑,而且最多会…


Hudi系列25: Flink SQL使用checkpoint恢复job异常
文章目录 一. 通过Flink SQL将MySQL数据写入Hudi二. 模拟Flink任务异常2.1 手工停止job2.2 指定checkpoint来恢复数据2.3 整个yarn-session上的任务恢复 三. 模拟源端异常3.1 手工关闭源端 MySQL 服务3.2 FLink任务查看 FAQ:1. checkpoint未写入数据2. checkpoint 失败3. 手工取…
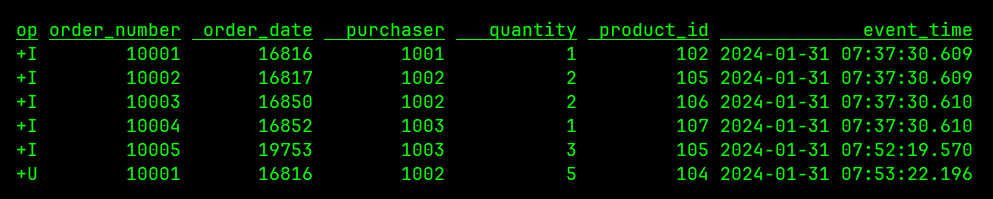
Flink 流式读取 Debezium CDC 数据写入 Hudi 表无法处理 -D / Delete 消息
问题场景是:使用 Kafka Connect 的 Debezium MySQL Source Connector 将 MySQL 的 CDC 数据 (Avro 格式)接入到 Kafka 之后,通过 Flink 读取并解析这些 CDC 数据,然后以流式方式写入到 Hudi 表中,测试中发现…

【大数据】Hudi 核心知识点详解(一)
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 &#x…
Hudi0.14.0集成Spark3.2.3(Spark SQL方式)
1 整合Hive For users who have Spark-Hive integration in their environment, this guide assumes that you have the appropriate settings configured to allow Spark to create tables and register in Hive Metastore. 我们使用 Hive添加第三方jar包方式总结 中**{HIVE_H…
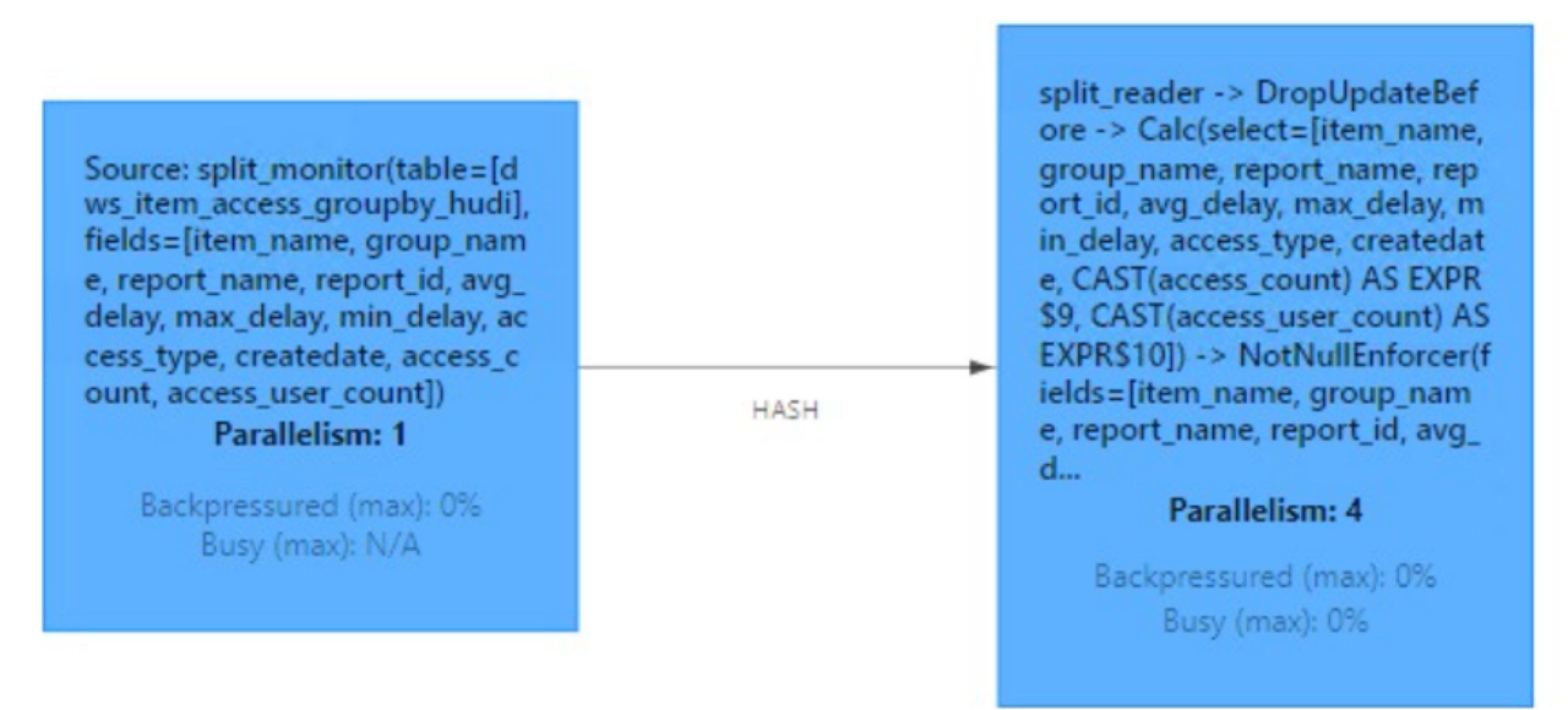
Hudi-集成Flink
文章目录集成Flink环境准备sql-client方式启动sql-client插入数据查询数据更新数据流式插入code 方式环境准备代码类型映射核心参数设置去重参数并发参数压缩参数文件大小Hadoop参数内存优化读取方式流读(Streaming Query)增量读取(Increment…
SparkSQL操作hudi
文章目录SparkSQL操作hudi1、登录2、创建普通表3、创建分区表4、从现有表创建表5、用查询结果创建新表(CTAS)6、插入数据7、查询数据8、修改数据9、合并数据10、删除数据11、覆盖写入12、修改数据表13、hudi分区命令SparkSQL操作hudi
1、登录
#spark 3.1
spark-sql --package…
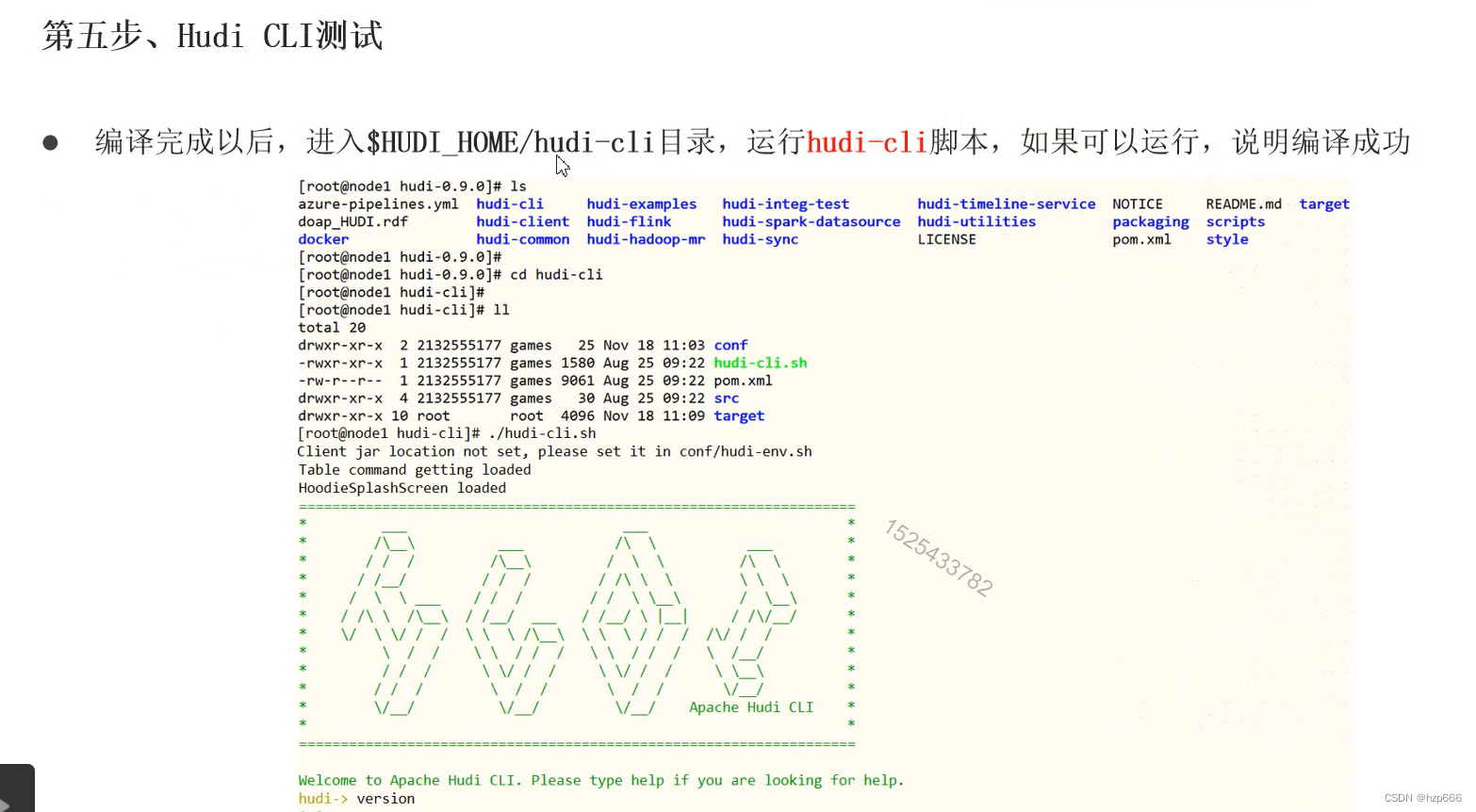
Hudi学习5:Hudi的helloworld-编译源码
hudi是使用java代码编写的
部署hudi 1. 下载源码
Download | Apache Hudi
https://dlcdn.apache.org/hudi/0.13.1/hudi-0.13.1.src.tgz
2.编译
安装maven 首先要先有JDK java8以上 配置镜像源 执行编译 测试
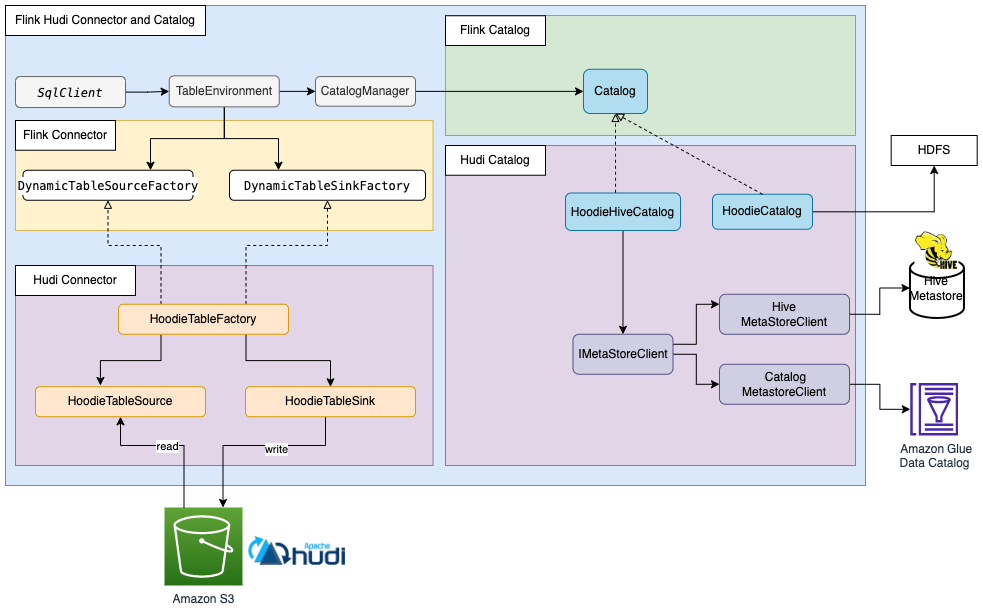
Flink Catalog 解读与同步 Hudi 表元数据的最佳实践
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
Apache Hudi初探(五)(与flink的结合)--Flink 中hudi clean操作
背景
本文主要是具体说说Flink中的clean操作的实现
杂说闲谈
在flink中主要是CleanFunction函数: Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);this.writeClient FlinkWriteClients.createWriteClient(conf,…
Hudi0.14.0 集成 Spark3.2.3(IDEA编码方式)
本次在IDEA下使用Scala语言进行开发,具体环境搭建查看文章 IDEA 下 Scala Maven 开发环境搭建。
1 环境准备
1.1 添加maven依赖
创建Maven工程,pom文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apa…

Hudi学习 6:Hudi使用
准备工作: 1.安装hdfs
https://mp.csdn.net/mp_blog/creation/editor/109689143
2.安装spark
spark学习4:spark安装_hzp666的博客-CSDN博客
3.安装Scala
Hudi学习6:安装和基本操作_hzp666的博客-CSDN博客 spark-shell 写入和读取hudi 2.…
Hudi第一章:编译安装
系列文章目录
Hudi第一章:编译安装 文章目录 系列文章目录前言一、环境准备1.JDK2.Maven1.上传并解压。2.修改源3.添加环境变量 二、hudi编译1.上传解压2.修改pom1.添加仓库2.修改依赖的组件版本 2.修改源码兼容hadoop33.手动安装Kafka依赖1.上传jar包2.install到m…
Apache Hudi初探(三)(与flink的结合)--flink写hudi的操作(真正的写数据)
背景
在之前的文章中Apache Hudi初探(二)(与flink的结合)–flink写hudi的操作(JobManager端的提交操作) 有说到写hudi数据会涉及到写hudi真实数据以及写hudi元数据,这篇文章来说一下具体的实现
写hudi真实数据
这里的操作就是在HoodieFlinkWriteClient.upsert方法:
public …