本篇博文从分析HBase架构开始,首先从架构中各个组成部分开始,接着从HBase写入过程角度入手,分析HFile的Compaction合并、Region的Split分裂过程及触发机制。
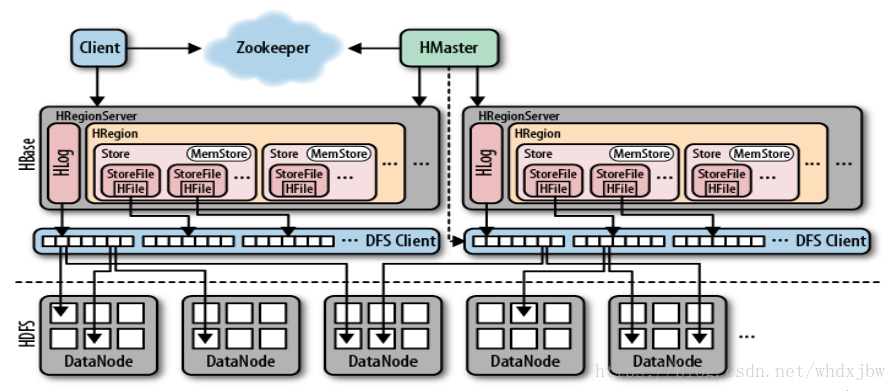
架构分析
1、HMaster
- 负责管理HBase元数据,即表的结构、表存储的Region等元信息。
- 负责表的创建,删除和修改(因为这些操作会导致HBase元数据的变动)。
- 负责为HRegionServer分配Region,分配好后也会将元数据写入相应位置(后面会详细讲述放在哪)
如果对可用性要求较高,它需要做HA高可用(通过Zookeeper)。但是HMaster不会去处理Client端的数据读写请求,因为这样会加大其负载压力,具体的读写请求它会交给HRegionServer来做。
2、HRegionServer
- 一个RegionServer里有多个Region。
- 处理Client端的读写请求(根据从HMaster返回的元数据找到对应的Region来读写数据)。
- 管理Region的Split分裂、StoreFile的Compaction合并
一个RegionServer管理着多个Region,在HBase运行期间,可以动态添加、删除HRegionServer
3、HRegion
- 一个HRegion里可能有1个或多个Store。
- HRegionServer维护一个HLog。
- HRegion是分布式存储和负载的最小单元。
- 表通常被保存在多个HRegionServer的多个Region中
因为HBase用于存储海量数据,故一张表中数据量非常之大,单机一般存不下这么大的数据,故HBase会将一张表按照行水平将大表划分为多个Region,每个Region保存表的一段连续数据。 初始只有1个Region,当一个Region增大到某个阈值后,便分割为两个。
4、Store
- Store是存储落盘的最小单元,由内存中的MemStore和磁盘中的若干StoreFile组成。
- 一个Store里有1个或多个StoreFile和一个memStore。
- 每个Store存储一个列族
HBase 读写过程
写过程
- Client访问ZK,根据ROOT表获取meta表所在Region的位置信息,并将该位置信息写入Client Cache。
- (注:为了加快数据访问速度,我们将元数据、Region位置等信息缓存在Client Cache中。)
- Client读取meta表,再根据meta表中查询得到的Namespace、表名和RowKey等相关信息,获取将要写入Region的位置信息(此过程即Region三层定位,如下图),最后client端会将meta表写入Client Cache。
- Client向上一步HRegionServer发出写请求,HRegionServer先将操作和数据写入HLog(预写日志,Write Ahead Log,WAL),再将数据写入MemStore,并保持有序。 (联想:HDFS中也是如此,EditLog写入时机也是在真实读写之前发生)
- 当MemStore的数据量超过阈值时,将数据溢写磁盘,生成一个StoreFile文件。
- 当Store中StoreFile的数量超过阈值时,将若干小StoreFile合并(Compact)为一个大StoreFile。
- 当Region中最大Store的大小超过阈值时,Region分裂(Split),等分成两个子Region
具体合并与分裂过程我们接下来讲解。

Region三层定位
读过程
- 获取将要读取Region的位置信息(同读的1、2步)。
- Client向HRegionServer发出读请求。
- HRegionServer先从MemStore读取数据,如未找到,再从StoreFile中读取。
StoreFile合并(Compaction)
目的:减少StoreFile数量,提升数据读取效率。
Compaction分为两种:
- major compaction
将Store下面**所有**StoreFile合并为一个StoreFile,此操作会删除其他版本的数据(不同时间戳的)
- minor compaction
选取Store下的**部分**StoreFile,将它们合并为一个StoreFile,此操作不会删除其他版本数据。
Region分割(Split)
目的:实现数据访问的负载均衡。
做法:利用Middle Key将当前Region划分为两个等分的子Region。需要指出的是:Split会产生大量的I/O操作,Split开始前和Split完成后,HRegionServer都会通知HMaster。Split完成后,由于Region映射关系已变更,故HRegionServer会更新meta表。
以上,即是HBase详细架构,以及在此架构上的读写操作的过程和可能发生的事件。后续博文会对HBase二级索引及BulkLoad相关内容进行进一步研究。
原文:https://blog.csdn.net/whdxjbw/article/details/81107285



