SARSA是一种on-policy算法,Q-Learning是一种off-policy算法。
关于on-policy和off-policy的定义,网上有很多不同的讨论,我认为, on-policy和off-policy的差异 在于 训练目标策略 所用到的数据
(有时候也表现为数据
)是不是当前目标策略(此时还没开始训练)得到的 ,如果是目标策略得到的,那么就是on-policy,如果不是,那么就是off-policy。
——https://zhuanlan.zhihu.com/p/384497349
SARSA的伪代码:

Q-Learning的伪代码:

区别在于更新方式:
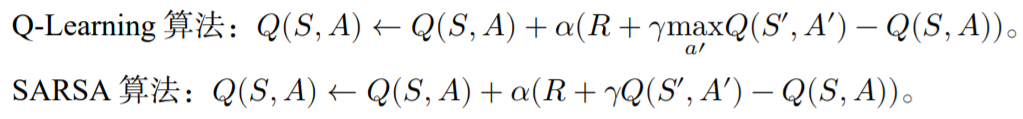
关于ε-greedy:
一种贪心选择算法,类似的还有UCB(最大置信度上界),在稍后的文章中再详细解释。
个人理解:
就是把奖励矩阵R通过反复迭代的方式,把值赋给价值矩阵Q,然后根据Q选择要转移的状态。
Q-learning很好的参考文章:
http://mnemstudio.org/path-finding-q-learning-tutorial.htm