定义
假设输入空间(特征向量)为X⊆Rn,输出空间为Y={-1, +1}。输入x∈X表示实例的特征向量,对应于输入空间的点;输出y∈Y表示示例的类别。由输入空间到输出空间的函数为
f(x)=sign(w·x + b) (1)
称为感知机。其中,参数w叫做权值向量,b称为偏置。w·x表示w和x的内积。sign为符号函数,即
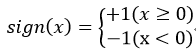 (2)
(2)
几何解释
感知机模型是线性分类模型,感知机模型的假设空间是定义在特征空间中的所有线性分类模型,即函数集合{f|f(x)=w·x+b}。线性方程 w·x+b=0对应于特征空间Rn中的一个超平面S,其中w是超平面的法向量,b是超平面的截踞。这个超平面把特征空间划分为两部分。位于两侧的点分别为正负两类。超平面S称为分离超平面,如下图:

损失函数的一个自然的选择是误分类的点的总数。但是这样得到的损失函数不是参数w、b的连续可导函数,不宜优化。损失函数的另一个选择是误分类点到分里面的距离之和。
这个推到过程可以去推导一下

首先,对于任意一点xo到超平面的距离为
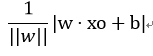 (3)
(3)
其次,对于误分类点(xi,yi)来说 -yi(w·xi+b)>0
因为wxi+b>0时,yi=−1,而当wxi+b<0时,yi=+1,因此,误分类点xi到超平面S的距离是:

这样,假设超平面S的总的误分类点集合为M,那么所有误分类点到S的距离之和为
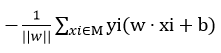 (4)
(4)
不考虑1/||w||(为什么要去掉呢?),就得到了感知机学习的损失函数。
![]() (5)
(5)
感知机学习是误分类驱动的,具体采用随机梯度下降法。首先,任意选定w0、b0,然后用梯度下降法不断极小化目标函数(6),极小化的过程不知一次性的把M中的所有误分类点梯度下降,而是一次随机选取一个误分类点使其梯度下降。
假设误分类集合M是固定的,那么损失函数L(w,b)的梯度由(7)(8)给出
![]() (7)
(7)
![]() (8)
(8)
随机选取一个误分类点(xi,yi),对w,b进行更新:
![]() (9)
(9)
![]() (10)
(10)
具体算法:
算法(感知机学习算法的原始形式)
| 输入:T={(x1,y1),(x2,y2)...(xN,yN)}(其中xi∈X=Rn,yi∈Y={-1, +1}, i=1,2...N,学习速率为η) 输出:w, b;感知机模型f(x)=sign(w·x+b) (1) 初始化w0,b0 (2) 在训练数据集中选取(xi, yi) (3) 如果yi(w xi+b)≤0 w = w + ηyixi b = b + ηyi (4) 转至(2) |
直观解释:当一个实例点被误分类时,调整w,b,使分离超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直至超越该点被正确分类。
IRIS示例:
from sklearn import datasets
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
iris = datasets.load_iris() # 加载Iris数据集。
print(type(iris))
X = iris.data[:, [2, 3]]#后面的两列数据
#iris是里面定义的一个数据集
y = iris.target # 标签已经转换成0,1,2了
#print(y)
#后面的随机数种子不知道是什么概念
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 为了看模型在没有见过数据集上的表现,随机拿出数据集中30%的部分做测试
#print(X_test)
# 为了追求机器学习和最优化算法的最佳性能,我们将特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train) # 估算每个特征的平均值和标准差
sc.mean_ # 查看特征的平均值,由于Iris我们只用了两个特征,结果是array([ 3.82857143, 1.22666667])
print(sc.mean_)
sc.scale_ # 查看特征的标准差,结果是array([ 1.79595918, 0.77769705])
print(sc.scale_)
X_train_std = sc.transform(X_train)
# 注意:这里我们要用同样的参数来标准化测试集,使得测试集和训练集之间有可比性
X_test_std = sc.transform(X_test)
# 训练感知机模型
from sklearn.linear_model import Perceptron
# n_iter:可以理解成梯度下降中迭代的次数
# eta0:可以理解成梯度下降中的学习率
# random_state:设置随机种子的,为了每次迭代都有相同的训练集顺序
ppn = Perceptron(n_iter=40, eta0=0.1, random_state=0)
print(ppn)
ppn.fit(X_train_std, y_train)
# 分类测试集,这将返回一个测试结果的数组
y_pred = ppn.predict(X_test_std)
print(y_pred)
# 计算模型在测试集上的准确性
#计算分类准确率
accuracy_score(y_test, y_pred)
-----------------------------执行结果-----------------------------------