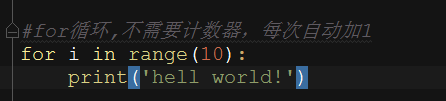
现在很多网站都是异步加载的方式加载数据,大部分都是json数据,如果不知道数据的传递过程,一些参数理不清头绪的话,又想要获取数据,那就比较难搞了,尤其是对于本渣渣级选手而言。

目标网址
https://www.keyshot.com/gallery/
需求
获取图片信息,需高清大图
经过简单浏览器抓包调试,可以获取到一些信息!
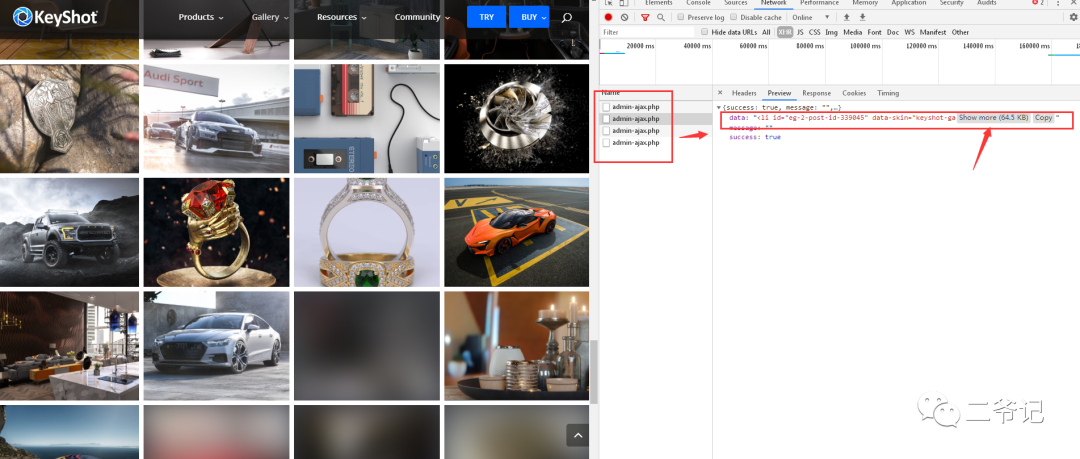
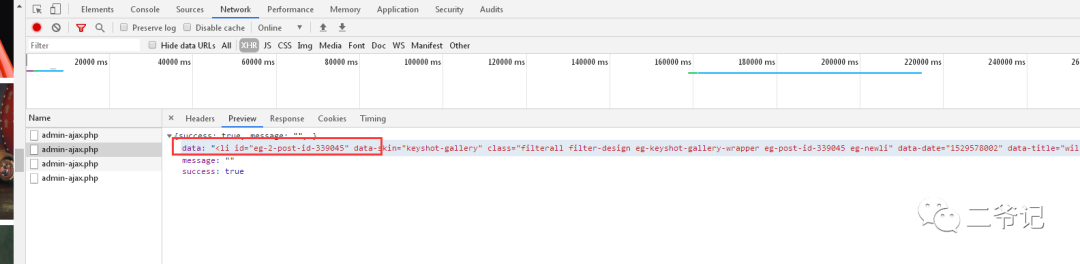
不想努力了,想了两个笨方法,好在数据量不大!
枚举法获取图片地址,爬取图片
1.枚举获取图片地址
代码示例
for i in range(10000):
if len(str(i))==1:
i=f'000{i}'
if len(str(i))==2:
i = f'00{i}'
if len(str(i))==3:
i = f'0{i}'
if len(str(i)) ==4:
i=i
print(i)
url=f"https://www.keyshot.com/wp-content/uploads/2016/06/keyshot-gallery-{i}.jpg"
if requests.get(url, headers=self.random_headers):
print("存在图片!")
图片链接:
https://www.keyshot.com/wp-content/uploads/2016/06/keyshot-gallery-0003.jpg
可以看到id与图片链接是存在关系的,所以,对于id进行迭代,同时进行了if判断!
2.图片下载
代码示例
def save_img(self, img_url, img_name, path):
os.makedirs(f'{path}/', exist_ok=True)
print("开始下载图片!")
print(f">>> 开始保存 {img_name} 图片")
r = requests.get(img_url, headers=self.random_headers,timeout=8)
with open(f'{path}/{img_name}.jpg', 'wb') as f:
f.write(r.content)
print(f">>> 保存 {img_name} 图片成功")
这里需要注意的是 timeout=8 属性一定需要标配,尤其是国外网站获取请求的话,不然容易卡死!
完整代码
# -*- coding: UTF-8 -*-
#微信:huguo00289
import requests
import random,os
class Httprequest(object):
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36Chrome 17.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0Firefox 4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
]
@property #把方法变成属性的装饰器
def random_headers(self):
return {
'User-Agent': random.choice(self.ua_list)
}
class Get_imgs(Httprequest):
def __init__(self):
self.path="key"
def getimgs(self):
for i in range(10000):
if len(str(i))==1:
i=f'000{i}'
if len(str(i))==2:
i = f'00{i}'
if len(str(i))==3:
i = f'0{i}'
if len(str(i)) ==4:
i=i
print(i)
url=f"https://www.keyshot.com/wp-content/uploads/2016/06/keyshot-gallery-{i}.jpg"
if requests.get(url, headers=self.random_headers):
print("存在图片!")
self.save_img(url, str(i), self.path)
#下载图片
def save_img(self, img_url, img_name, path):
os.makedirs(f'{path}/', exist_ok=True)
print("开始下载图片!")
print(f">>> 开始保存 {img_name} 图片")
r = requests.get(img_url, headers=self.random_headers,timeout=8)
with open(f'{path}/{img_name}.jpg', 'wb') as f:
f.write(r.content)
print(f">>> 保存 {img_name} 图片成功")
if __name__=='__main__':
spider=Get_imgs()
spider.getimgs()
手动获取json数据包,爬取图片
1.正则获取图片地址
代码示例
img_urls=[]
zeimg=r'href="(.+?)"'
imgs=re.findall(zeimg,str(datas),re.S)
for img in imgs:
if "www.keyshot.com" in img:
img_urls.append(img)
2.多线程下载图片,这里使用了线程池技术
代码示例
def main():
img_urls=get_imgs()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(save_img, img_urls)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
完整代码
#keyshot图片采集
# -*- coding: UTF-8 -*-
#微信:huguo00289
import requests,re,os,random
from multiprocessing.dummy import Pool as ThreadPool
def get_imgs():
datas="""
data: "↵ ↵
↵↵ ↵↵ ↵ Dmitrij Leppée↵ ↵ ↵↵↵↵ ↵↵↵ ↵↵ ↵ Tiho Ramovic↵ ↵ ↵↵↵↵ ↵↵↵ ↵↵ ↵ Vitaly Bulgarov↵ ↵ ↵↵↵↵ ↵↵↵ ↵↵ ↵ Maarten Verhoeven↵ ↵ ↵↵↵↵ ↵↵↵ ↵↵ ↵ Philippe Vanagt↵ ↵ ↵↵↵"
message: ""
success: true
"""
img_urls=[]
zeimg=r'href="(.+?)"'
imgs=re.findall(zeimg,str(datas),re.S)
for img in imgs:
if "www.keyshot.com" in img:
img_urls.append(img)
print(len(img_urls))
return img_urls
#下载图片
def save_img(img_url):
path = "key"
ua_list = [
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36Chrome 17.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0Firefox 4.0.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
]
os.makedirs(f'{path}/', exist_ok=True)
img_name=img_url.split('/')[-1]
print("开始下载图片!")
print(f">>> 开始保存 {img_name} 图片")
r = requests.get(img_url,headers={'User-Agent':random.choice(ua_list)},timeout=8)
with open(f'{path}/{img_name}', 'wb') as f:
f.write(r.content)
print(f">>> 保存 {img_name} 图片成功")
def main():
img_urls=get_imgs()
try:
# 开4个 worker,没有参数时默认是 cpu 的核心数
pool = ThreadPool()
results = pool.map(save_img, img_urls)
pool.close()
pool.join()
print("采集所有图片完成!")
except:
print("Error: unable to start thread")
if __name__=='__main__':
main()

微信公众号:二爷记
不定时分享python源码及工具