文章目录
- 文件操作
- 文件编码
- 什么是编码
- 为什么要使用编码
- 文件的读取
- open
- model常用的三种基础访问模式
- 读操作相关方法
- 文件的写入
- 注意
- 代码示例
- 异常
- 定义
- 异常捕获
- 捕获指定异常
- 捕获多个异常
- 捕获所有异常
- 异常else
- 异常finally
- 异常的传递
- python 模块
- 定义
- 模块的导入
- import模块名
- from 模块名 import 功能名
- 使用*导入time的sleep功能
- 使用as给特定功能加上别名
- 自定义模块
- 创建自定义模块举例
- `__name__` 变量
- `__all__` 变量
- 注意
- Python包
- 自定义包
- 定义
- 创建包
- 导入包
- 使用import导入
- 使用from import导入
- 导入模块中
- 安装第三方包
- 常见第三方包
- 安装第三方包
- 综合练习
- 需求
- 实现
文件操作
文件编码
什么是编码
-
编码就是一种规则集合,记录了内容和二进制间进行互相转换的规则
-
最常用的是UTF-8编码
为什么要使用编码
-
计算机内部保存的都是0和1,所以需要将内容全部转换为0和1才能识别
-
读取时需要将计算机中保存的0和1转为内容
文件的读取
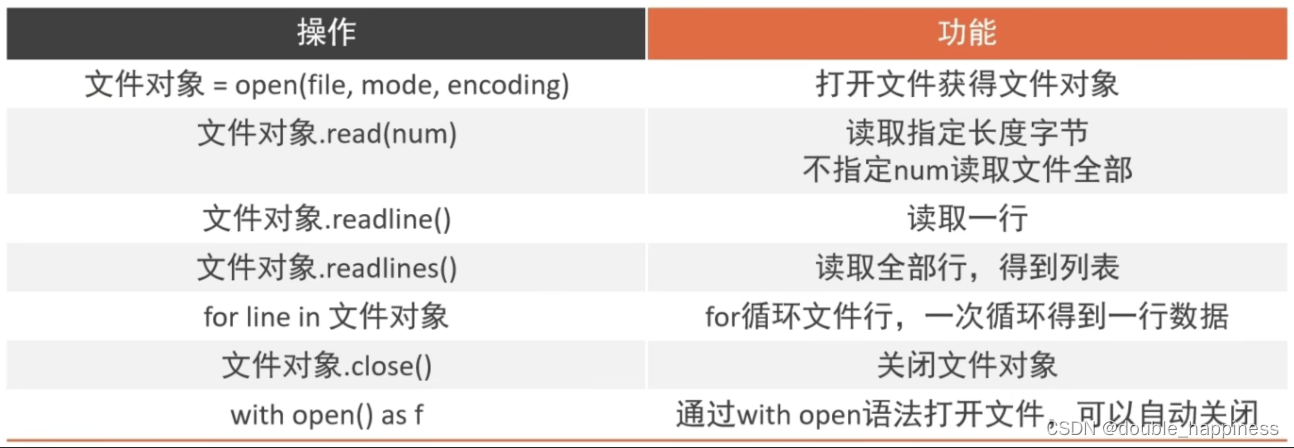
open
- 语法
python">open(name, mode, encoding)
name 要打开的目标文件名的字符串
mode 打开文件的模式:只读、写入、追加
encoding 编码格式,推荐使用UTF8
model常用的三种基础访问模式

读操作相关方法
- read方法
python">文件对象.read(num)
num 表示要从文件中读取的数据长度,单位是字节,如果没有传,读取文件中所有的数据
-
readlines():可以按照行的方式把整个文件的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
-
readline()读取文件的一行
-
for循环读取文件行
-
close()关闭文件对象
-
with open语法:用于打开文件并在使用完毕后自动关闭文件
- 代码示例
python"># *_*coding:utf-8 *_*
# 打开文件
f = open("./read_file.py", 'r', encoding="UTF-8")
# 读取文件
print(f'读取50个字节的结果{f.read(50)}')
# 在程序中多次调用read,下一次会从上一次读的偏移结尾继续读
print(f'读取全部字节的结果{f.read()}')
# readlines读取文件的全部行,封装到列表中
print(f'读取文件的全部行{f.readlines()}')
# readline一次读取文件一行
line1 = f.readline()
line2 = f.readline()
line3 = f.readline()
print(f'第一行数据是:{line1}')
print(f'第二行数据是:{line2}')
print(f'第三行数据是:{line3}')
# 关闭文件
f.close()
# for循环读取文件行
for line in open("./read_file.py", "r"):
print(line)
# with open语法
with open("./read_file.py", "r", encoding="UTF-8") as f:
print(f'{f.readlines()}')
文件的写入
注意
-
直接调用write方法,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
-
当调用flush的时候,内容会真正写入文件
-
目的:避免频繁磁盘操作,导致效率下降
-
close方法内置了flush功能
-
w模式
-
文件不存在则创建
-
文件存在则清空
-
-
a模式
-
文件不存在则创建
-
文件存在则追加尾部写
-
代码示例
python"># *_*coding:utf-8 *_*
# open打开文件,使用覆盖写操作
f = open("test.txt", "w", encoding="UTF-8")
# write写入
f.write("123456789")
# flush刷新
f.flush()
# 关闭文件
f.close()
# open打开文件,使用追加写操作
f = open("test1.txt", "a", encoding="UTF-8")
# write写入
f.write("123456789")
# flush刷新
f.flush()
# 关闭文件
f.close()
异常
定义
- 当检测到一个错误时,Python解释器就无法继续运行了,反而出现一些错误的提示,这就是所谓的异常
异常捕获
-
作用:提前假设某处会出现异常,做好提前准备,当真的出现异常时,可以有后续手段
-
基本语法
python">try:
可能发生异常的代码块
except:
出现异常后的代码块
- 代码示例:打开一个不存在的文件
python">try:
f = open("xxx.txt", 'r')
except:
print("open file err")
捕获指定异常
-
注意:
-
如果尝试执行的代码的异常类型和捕获的异常类型不一致,则无法捕获异常
-
一般try下面只放一行尝试执行的代码
-
-
语法:
python">try:
print(name)
except NameError as e:
print('name变量名称未定义错误')
- 代码示例
python">try:
print(name)
# as e是给NameError类型起别名
except NameError as e:
print('name变量未定义错误')
捕获多个异常
- 代码示例
python"># 捕获多个异常
try:
print(name)
# as e是给NameError类型起别名,e中记录了异常的具体信息
except (NameError, ZeroDivisionError) as e:
print('name变量未定义错误或者除0异常')
捕获所有异常
- 代码示例
python"># 捕获所有异常
try:
print(name)
# 方式一:通过捕获Exception异常,Exception是顶级异常
except Exception as e:
print('name变量未定义错误')
try:
print(name)
# 方式二:不指定具体的异常直接捕获
except:
print('name变量未定义错误')
异常else
-
else表示的是如果没有异常要执行的代码
-
代码示例
python"># 异常else
try:
print(name)
# as e是给NameError类型起别名,e中记录了异常的具体信息
except (NameError, ZeroDivisionError) as e:
print('name变量未定义错误或者除0异常')
else:
print("未发生异常")
异常finally
-
finally表示的是无论是否异常都要执行的代码
-
代码示例
python"># 异常finally
try:
print(name)
# as e是给NameError类型起别名,e中记录了异常的具体信息
except (NameError, ZeroDivisionError) as e:
print('name变量未定义错误或者除0异常')
else:
print("未发生异常")
finally:
print("总会执行我")
异常的传递
-
异常是具有传递性的
-
内层的异常如果没有被捕获会沿着调用链一直向上抛直到main函数
-
代码示例
python"># *_*coding:utf-8 *_*
def func1():
print("func1 start")
1 / 0
print("func1 end")
def func2():
print("func2 start")
func1()
print("func2 end")
def main():
try:
func2()
except Exception as e:
print(e)
main()
python__290">python 模块
定义
-
Python模块是一个Python文件,以.py结尾,模块能定义类、函数和变量,模块里面也能包含可执行的代码
-
作用:模块就是一个工具包
模块的导入
-
模块在使用之前需要先导入
-
语法
python">[from 模块名] import [模块|类|变量|函数|*] [as 别名]
- 常用组合方式
python">import 模块名
from 模块名 import 类、变量、方法等
from 模块名 import *
import 模块名 as 别名
from 模块名 import 功能名 as 别名
import模块名
- 基本语法
python">import 模块名
import 模块名1,模块名2
- 代码示例
python"># 导入时间模块
import time
print("satrt")
# 程序睡眠3s
time.sleep(3)
print("end")
from 模块名 import 功能名
- 代码示例
python">from time import sleep
print("satrt")
# 程序睡眠3s
sleep(3)
print("end")
使用*导入time的sleep功能
- 代码示例
python">from time import *
print("satrt")
# 程序睡眠3s
sleep(3)
print("end")
使用as给特定功能加上别名
- 代码示例
python">import time as t
print("satrt")
# 程序睡眠3s
t.sleep(3)
print("end")
自定义模块
创建自定义模块举例
- 创建
my_module.py
python">def test(a, b):
print(a + b)
- 创建
test_my_module.py
python">import my_module
my_module.test(1, 2)
__name__ 变量
-
在当前模块中执行时,才会生效,外部导入时不会执行
-
代码示例
python">def test(a, b):
print(a + b)
if __name__ == '__main__':
test(1, 1)
__all__ 变量
-
如果一个模块中有
__all__变量,当使用from xxx import *,时只能导入这个列表中的元素,没有all时默认导入的是所有,有all时只导入all中的 -
创建
my_module.py
python">__all__ = ['test1']
def test(a, b):
print(a + b)
def test1(a, b):
print(a + b)
- 创建
test_my_module.py
python">from my_module import *
test1(1, 1)
# NameError: name 'test' is not defined
# test(1, 1)
注意
- 不同模块,同名的功能,如果都被导入,那么后导入的会覆盖先导入的
Python包
自定义包
定义
-
从物理上看,包就是一个文件夹,在该文件夹下包含了一个
__init__.py文件,该文件夹可用于包含多个模块文件 -
从逻辑上看,包的本质依然是模块
创建包
-
右键New->Python Package->输入包名
-
编写对应模块文件
- 新建
my_module1.py
python"># *_*coding:utf-8 *_* def info_print1(): print('my_module1')- 新建
my_module2.py
python"># *_*coding:utf-8 *_* def info_print2(): print('my_module2') - 新建
导入包
使用import导入
- 在
my_package同级创建一个test_my_package.py文件
python"># *_*coding:utf-8 *_*
import my_package.my_module1
import my_package.my_module2
# 包中的my_module1模块的info_print方法
my_package.my_module1.info_print1()
# 包中的my_module2模块的info_print方法
my_package.my_module2.info_print2()
使用from import导入
python">from my_package import my_module1
from my_package import my_module2
my_module1.info_print1()
my_module2.info_print2()
导入模块中
python">from my_package.my_module1 import info_print1
from my_package.my_module2 import info_print2
info_print1()
info_print2()
安装第三方包
常见第三方包

安装第三方包
-
命令:
pip install 包名 -
示例

综合练习
需求

实现
-
新建
my_utils包 -
新建
str_utils.py文件
python"># *_*coding:utf-8 *_*
def str_reverse(s):
reversed(s)
return s
def substr(s, x, y):
return s[x:y]
- 新建
file_utils.py文件
python"># *_*coding:utf-8 *_*
def print_file_info(file_name):
try:
f = open(file_name, "r", encoding='UTF-8')
except Exception as e:
print(e)
finally:
f.close()
def append_to_file(file_name, data):
f1 = open(file_name, 'a', encoding='UTF-8')
f1.write(data)
f1.close()
- 测试:在my_utils同级新建
test_my_utils.py
python"># *_*coding:utf-8 *_*
from my_utils import str_util
from my_utils import file_util
print(f'反转后的结果是:{str_util.str_reverse("abc")}')
print(f'取子串后后的结果是:{str_util.substr("123456789", 2, 7)}')
file_util.print_file_info("aa.txt")
file_util.append_to_file("aa.txt", "这是一条追加内容")