点击查看:协程上下文与调度器 中文官网
点击查看:协程上下文与调度器 英文官网
协程总是运行在一些以 CoroutineContext 类型为代表的上下文中,它们被定义在了 Kotlin 的标准库里。
协程上下文是各种不同元素的集合。其中主元素是协程中的 Job, 我们在前面的文档中见过它以及它的调度器,而本文将对它进行介绍。
调度器与线程
协程上下文包含一个 协程调度器 (参见 CoroutineDispatcher)它确定了相关的协程在哪个线程或哪些线程上执行。协程调度器可以将协程限制在一个特定的线程执行,或将它分派到一个线程池,亦或是让它不受限地运行。
所有的协程构建器诸如 launch 和 async 接收一个可选的 CoroutineContext 参数,它可以被用来显式的为一个新协程或其它上下文元素指定一个调度器。
尝试下面的示例:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
launch { // context of the parent, main runBlocking coroutine
println("main runBlocking : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Unconfined) { // not confined -- will work with main thread
println("Unconfined : I'm working in thread ${Thread.currentThread().name}")
}
launch(Dispatchers.Default) { // will get dispatched to DefaultDispatcher
println("Default : I'm working in thread ${Thread.currentThread().name}")
}
launch(newSingleThreadContext("MyOwnThread")) { // will get its own new thread
println("newSingleThreadContext: I'm working in thread ${Thread.currentThread().name}")
}
}
运行结果

当调用 launch { …… } 时不传参数,它从启动了它的 CoroutineScope 中承袭了上下文(以及调度器)。在这个案例中,它从 main 线程中的 runBlocking 主协程承袭了上下文。
Dispatchers.Unconfined 是一个特殊的调度器且似乎也运行在 main 线程中,但实际上, 它是一种不同的机制,这会在后文中讲到。
当协程在 GlobalScope 中启动时,使用的是由 Dispatchers.Default 代表的默认调度器。 默认调度器使用共享的后台线程池。 所以 launch(Dispatchers.Default) { …… } 与 GlobalScope.launch { …… } 使用相同的调度器。
newSingleThreadContext 为协程的运行启动了一个线程。 一个专用的线程是一种非常昂贵的资源。 在真实的应用程序中两者都必须被释放,当不再需要的时候,使用 close 函数,或存储在一个顶层变量中使它在整个应用程序中被重用。
非受限调度器 vs 受限调度器
Dispatchers.Unconfined 协程调度器在调用它的线程启动了一个协程,但它仅仅只是运行到第一个挂起点。挂起后,它恢复线程中的协程,而这完全由被调用的挂起函数来决定。非受限的调度器非常适用于执行不消耗 CPU 时间的任务,以及不更新局限于特定线程的任何共享数据(如UI)的协程。
另一方面,该调度器默认继承了外部的 CoroutineScope。 runBlocking 协程的默认调度器,特别是, 当它被限制在了调用者线程时,继承自它将会有效地限制协程在该线程运行并且具有可预测的 FIFO 调度。
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
launch(Dispatchers.Unconfined) { // not confined -- will work with main thread
println("Unconfined : I'm working in thread ${Thread.currentThread().name}")
delay(500)
println("Unconfined : After delay in thread ${Thread.currentThread().name}")
}
launch { // context of the parent, main runBlocking coroutine
println("main runBlocking: I'm working in thread ${Thread.currentThread().name}")
delay(1000)
println("main runBlocking: After delay in thread ${Thread.currentThread().name}")
}
}
运行结果

所以,该协程的上下文继承自 runBlocking {…} 协程并在 main 线程中运行,当 delay 函数调用的时候,非受限的那个协程在默认的执行者线程中恢复执行。
非受限的调度器是一种高级机制,可以在某些极端情况下提供帮助而不需要调度协程以便稍后执行或产生不希望的副作用, 因为某些操作必须立即在协程中执行。 非受限调度器不应该在通常的代码中使用。
调试协程与线程
协程可以在一个线程上挂起并在其它线程上恢复。 如果没有特殊工具,甚至对于一个单线程的调度器也是难以弄清楚协程在何时何地正在做什么事情。
用 IDEA 调试
Kotlin 插件的协程调试器简化了 IntelliJ IDEA 中的协程调试.
调试适用于 1.3.8 或更高版本的 kotlinx-coroutines-core。
调试工具窗口包含 Coroutines 标签。在这个标签中,你可以同时找到运行中与已挂起的协程的相关信息。 这些协程以它们所运行的调度器进行分组。
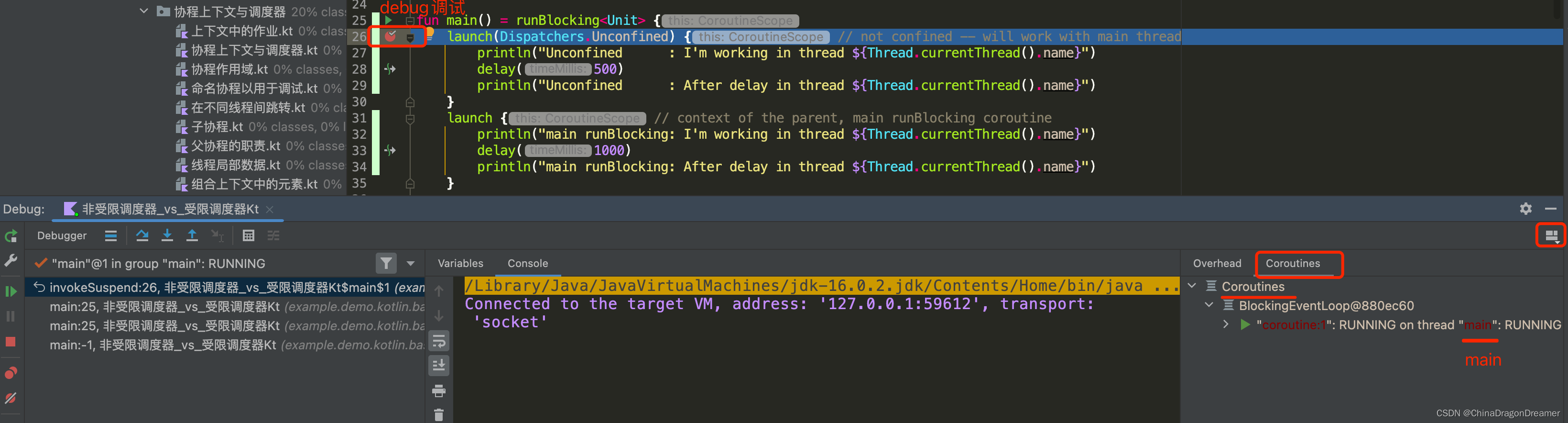
使用协程调试器,你可以:
- 检查每个协程的状态。
- 查看正在运行的与挂起的的协程的局部变量以及捕获变量的值。
- 查看完整的协程创建栈以及协程内部的调用栈。栈包含所有带有变量的
帧,甚至包含那些在标准调试期间会丢失的栈帧。- 获取包含每个协程的状态以及栈信息的完整报告。要获取它,请右键单击 Coroutines 选项卡,然后点击 Get Coroutines Dump。
要开始协程调试,你只需要设置断点并在调试模式下运行应用程序即可。
用日志调试
另一种调试线程应用程序而不使用协程调试器的方法是让线程在每一个日志文件的日志声明中打印线程的名字。这种特性在日志框架中是普遍受支持的。但是在使用协程时,单独的线程名称不会给出很多协程上下文信息,所以 kotlinx.coroutines 包含了调试工具来让它更简单。
使用 -Dkotlinx.coroutines.debug JVM 参数运行下面的代码:
提醒: Debug模式运行下面的代码
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
val a = async {
log("I'm computing a piece of the answer")
6
}
val b = async {
log("I'm computing another piece of the answer")
7
}
log("The answer is ${a.await() * b.await()}")
}
运行结果‘
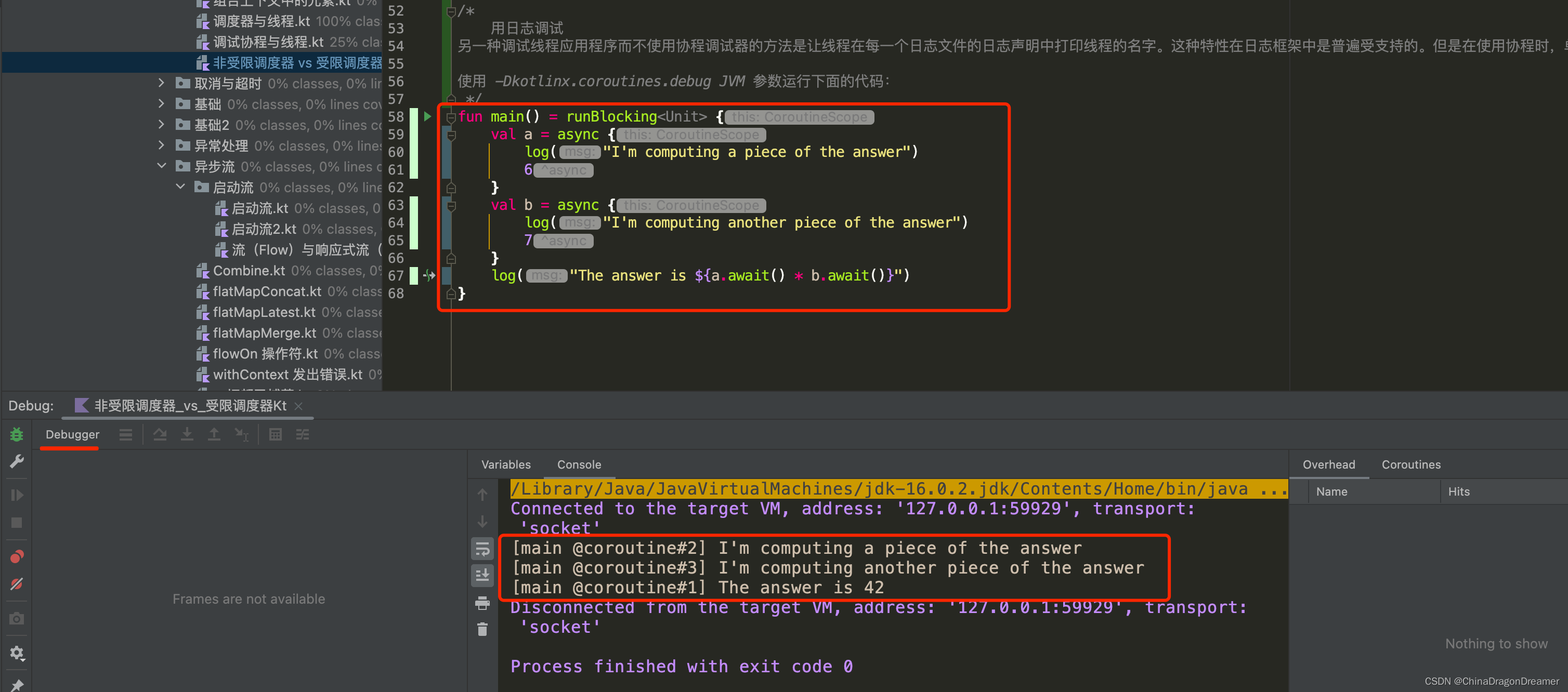
这里有三个协程,包括 runBlocking 内的主协程 (#1) , 以及计算延期的值的另外两个协程 a (#2) 和 b (#3)。 它们都在 runBlocking 上下文中执行并且被限制在了主线程内。 这段代码的输出如下:
这个 log 函数在方括号种打印了线程的名字,并且你可以看到它是 main 线程,并且附带了当前正在其上执行的协程的标识符。这个标识符在调试模式开启时,将连续分配给所有创建的协程。
当 JVM 以 -ea 参数配置运行时,调试模式也会开启。 你可以在 DEBUG_PROPERTY_NAME 属性的文档中阅读有关调试工具的更多信息。

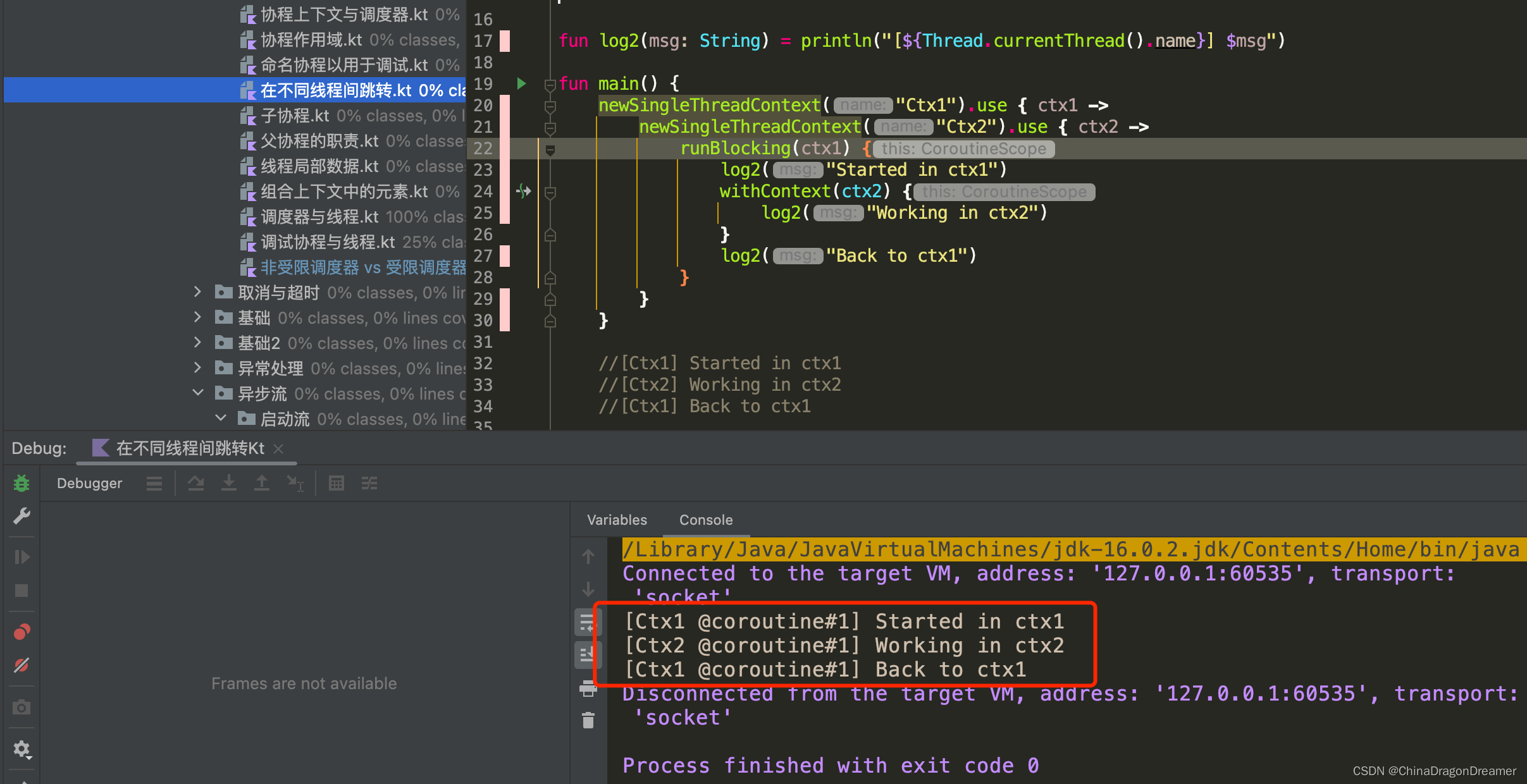
在不同线程间跳转
使用 -Dkotlinx.coroutines.debug JVM 参数运行下面的代码
提醒: Debug模式运行下面的代码
import kotlinx.coroutines.*
fun log2(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() {
newSingleThreadContext("Ctx1").use { ctx1 ->
newSingleThreadContext("Ctx2").use { ctx2 ->
runBlocking(ctx1) {
log2("Started in ctx1")
withContext(ctx2) {
log2("Working in ctx2")
}
log2("Back to ctx1")
}
}
}
}
它演示了一些新技术。其中一个使用 runBlocking 来显式指定了一个上下文,并且另一个使用 withContext 函数来改变协程的上下文,而仍然驻留在相同的协程中,正如可以在下面的输出中所见到的:
注意,在这个例子中,当我们不再需要某个在 newSingleThreadContext 中创建的线程的时候, 它使用了 Kotlin 标准库中的 use 函数来释放该线程。
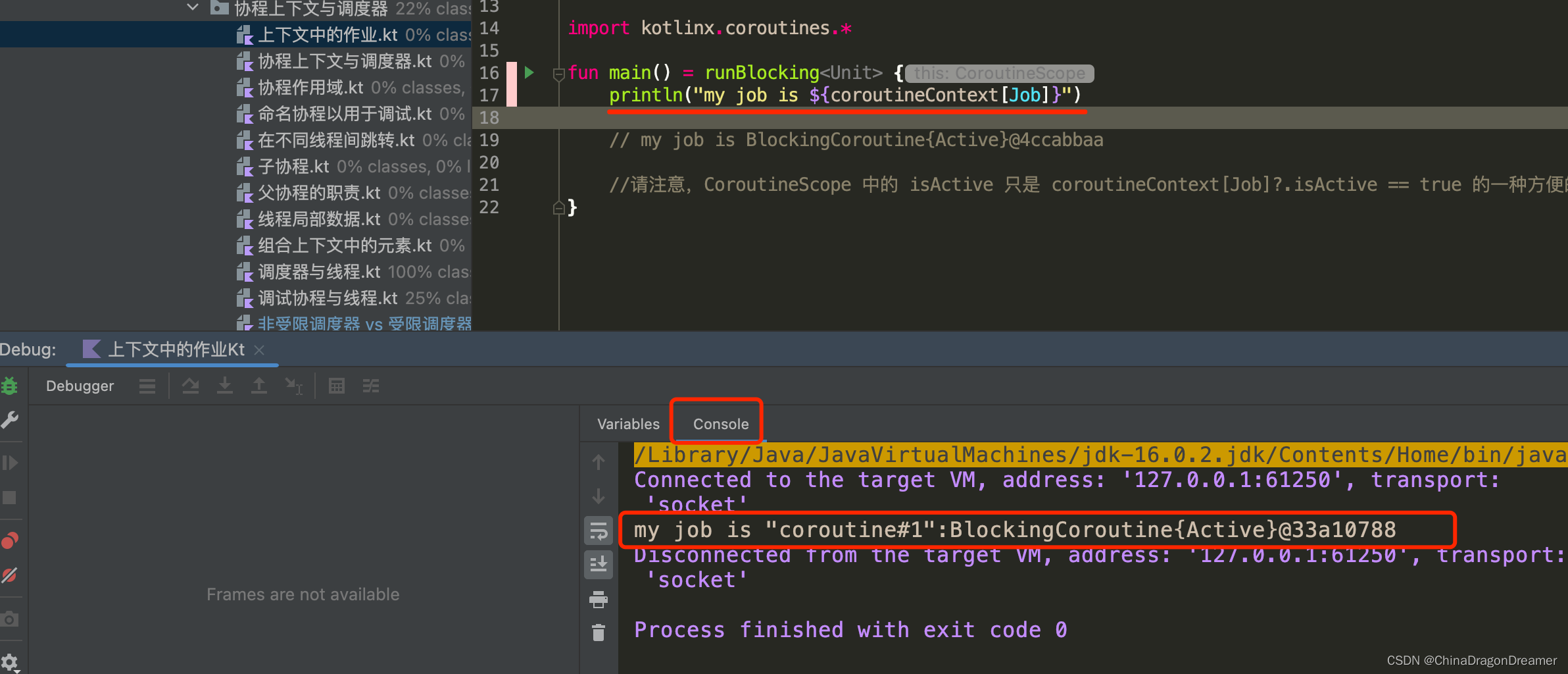
上下文中的作业
协程的 Job 是上下文的一部分,并且可以使用 coroutineContext [Job] 表达式在上下文中检索它:
使用 -Dkotlinx.coroutines.debug JVM 参数运行下面的代码
提醒: Debug模式运行下面的代码
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
println("my job is ${coroutineContext[Job]}")
}
Debug模式输出如下这些信息
请注意,CoroutineScope 中的 isActive 只是 coroutineContext[Job]?.isActive == true 的一种方便的快捷方式。
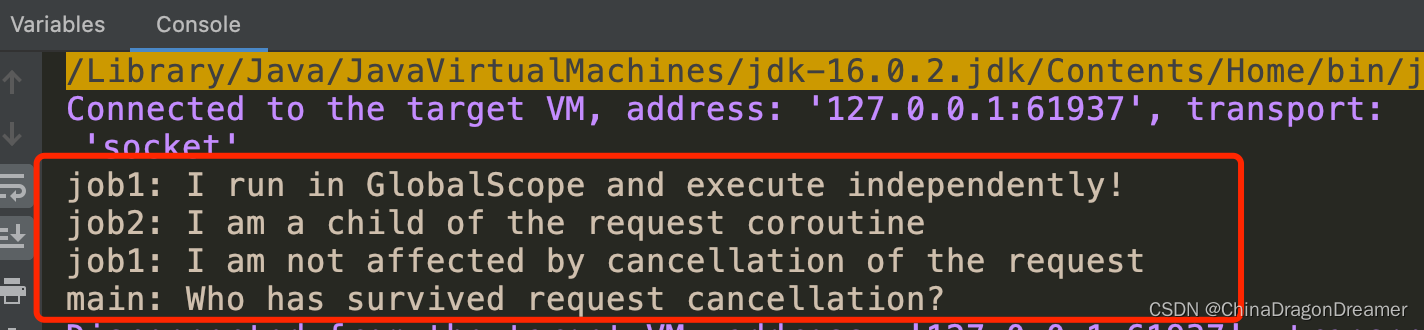
子协程
当一个协程被其它协程在 CoroutineScope 中启动的时候, 它将通过 CoroutineScope.coroutineContext 来承袭上下文,并且这个新协程的 Job 将会成为父协程作业的 子 作业。当一个父协程被取消的时候,所有它的子协程也会被递归的取消。
然而,当使用 GlobalScope 来启动一个协程时,则新协程的作业没有父作业。 因此它与这个启动的作用域无关且独立运作。
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
// launch a coroutine to process some kind of incoming request 启动一个协程来处理某种传入请求(request)
val request = launch {
// it spawns two other jobs, one with GlobalScope 孵化了两个子作业, 其中一个通过 GlobalScope 启动
GlobalScope.launch {
println("job1: I run in GlobalScope and execute independently!")
delay(1000)
println("job1: I am not affected by cancellation of the request")
}
// and the other inherits the parent context 另一个则承袭了父协程的上下文
launch {
delay(100)
println("job2: I am a child of the request coroutine")
delay(1000)
println("job2: I will not execute this line if my parent request is cancelled")
}
}
delay(500)
request.cancel() // cancel processing of the request 取消请求(request)的执行
delay(1000) // delay a second to see what happens 延迟一秒钟来看看发生了什么
println("main: Who has survived request cancellation?")
}
运行结果
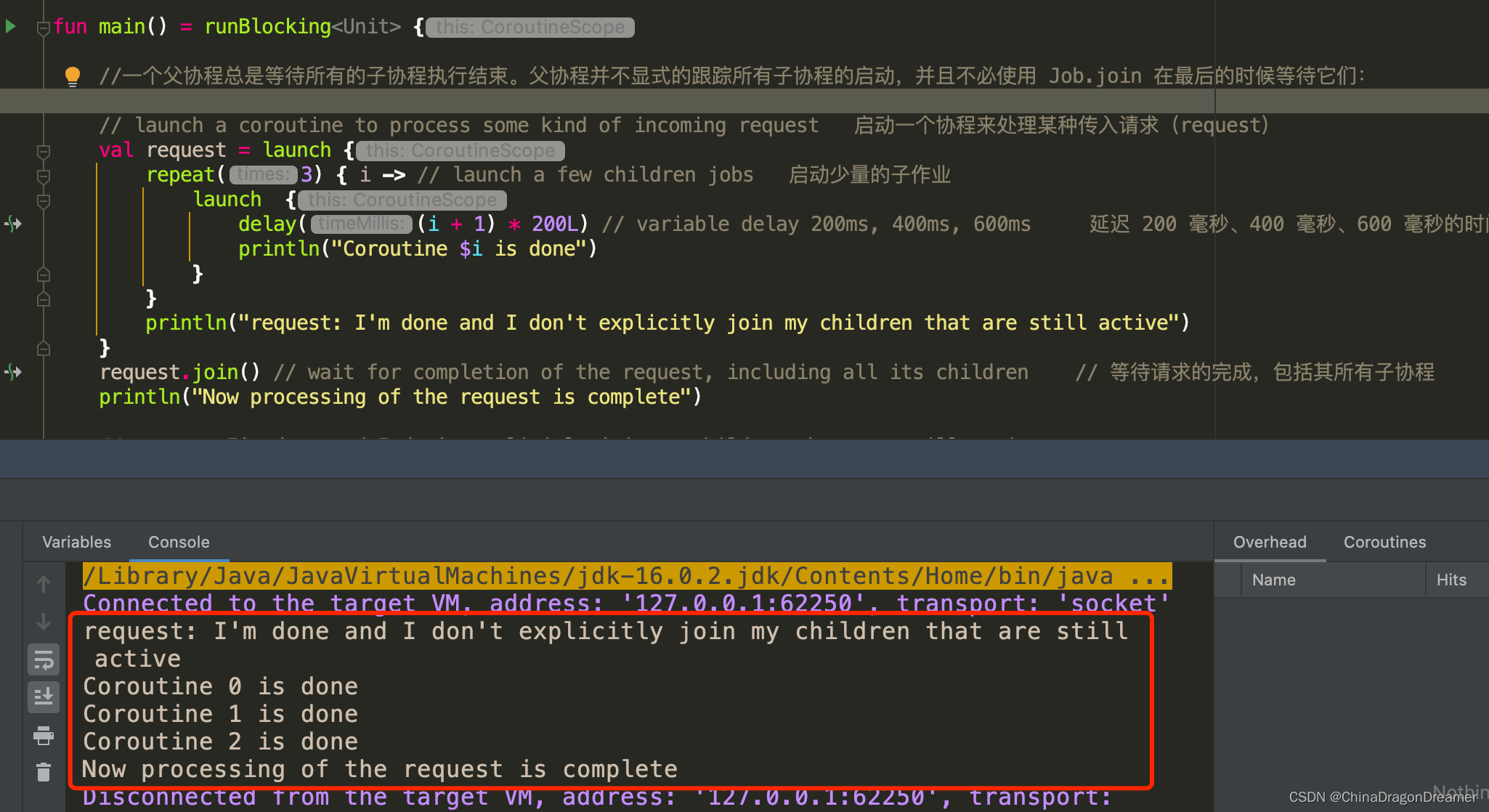
父协程的职责
一个父协程总是等待所有的子协程执行结束。父协程并不显式的跟踪所有子协程的启动,并且不必使用 Job.join 在最后的时候等待它们:
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//一个父协程总是等待所有的子协程执行结束。父协程并不显式的跟踪所有子协程的启动,并且不必使用 Job.join 在最后的时候等待它们:
// launch a coroutine to process some kind of incoming request 启动一个协程来处理某种传入请求(request)
val request = launch {
repeat(3) { i -> // launch a few children jobs 启动少量的子作业
launch {
delay((i + 1) * 200L) // variable delay 200ms, 400ms, 600ms 延迟 200 毫秒、400 毫秒、600 毫秒的时间
println("Coroutine $i is done")
}
}
println("request: I'm done and I don't explicitly join my children that are still active")
}
request.join() // wait for completion of the request, including all its children // 等待请求的完成,包括其所有子协程
println("Now processing of the request is complete")
}
运行结果
命名协程以用于调试
当协程经常打印日志并且你只需要关联来自同一个协程的日志记录时, 则自动分配的 id 是非常好的。然而,当一个协程与特定请求的处理相关联时或做一些特定的后台任务,最好将其明确命名以用于调试目的。 CoroutineName 上下文元素与线程名具有相同的目的。当调试模式开启(使用 -Dkotlinx.coroutines.debug JVM 参数运行)时,它被包含在正在执行此协程的线程名中。
使用 -Dkotlinx.coroutines.debug JVM 参数运行下面的代码
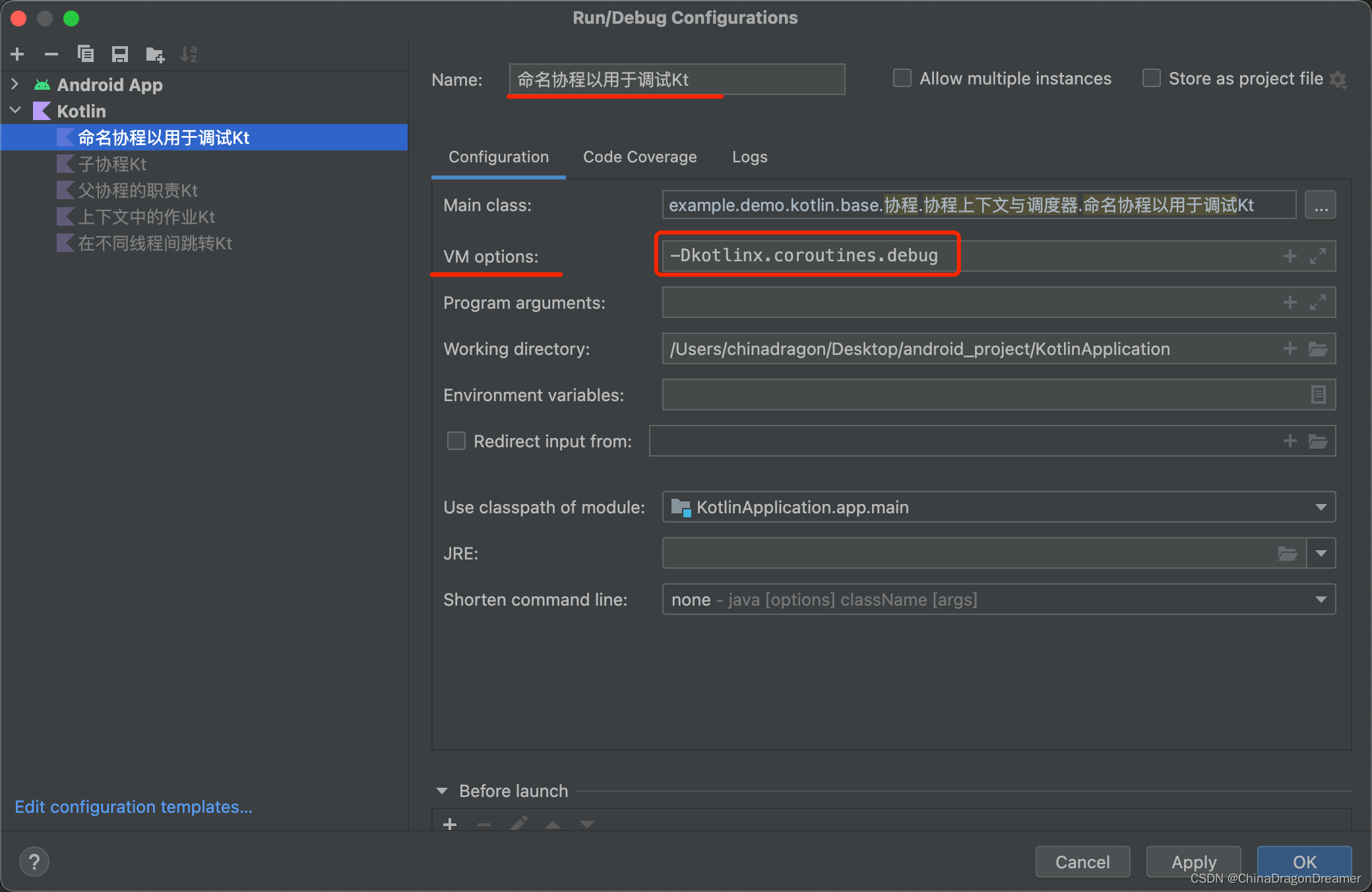
import kotlinx.coroutines.*
fun log3(msg: String) = println("[${Thread.currentThread().name}] $msg")
fun main() = runBlocking(CoroutineName("main")) {
// 当协程经常打印日志并且你只需要关联来自同一个协程的日志记录时, 则自动分配的 id 是非常好的。然而,当一个协程与特定请求的处理相关联时或做一些特定的后台任务,
// 最好将其明确命名以用于调试目的。 CoroutineName 上下文元素与线程名具有相同的目的。当调试模式开启时,它被包含在正在执行此协程的线程名中。
log3("Started main coroutine")
// run two background value computations
val v1 = async(CoroutineName("v1coroutine")) {
delay(500)
log3("Computing v1")
252
}
val v2 = async(CoroutineName("v2coroutine")) {
delay(1000)
log3("Computing v2")
6
}
log3("The answer for v1 / v2 = ${v1.await() / v2.await()}")
}
Debug模式运行结果
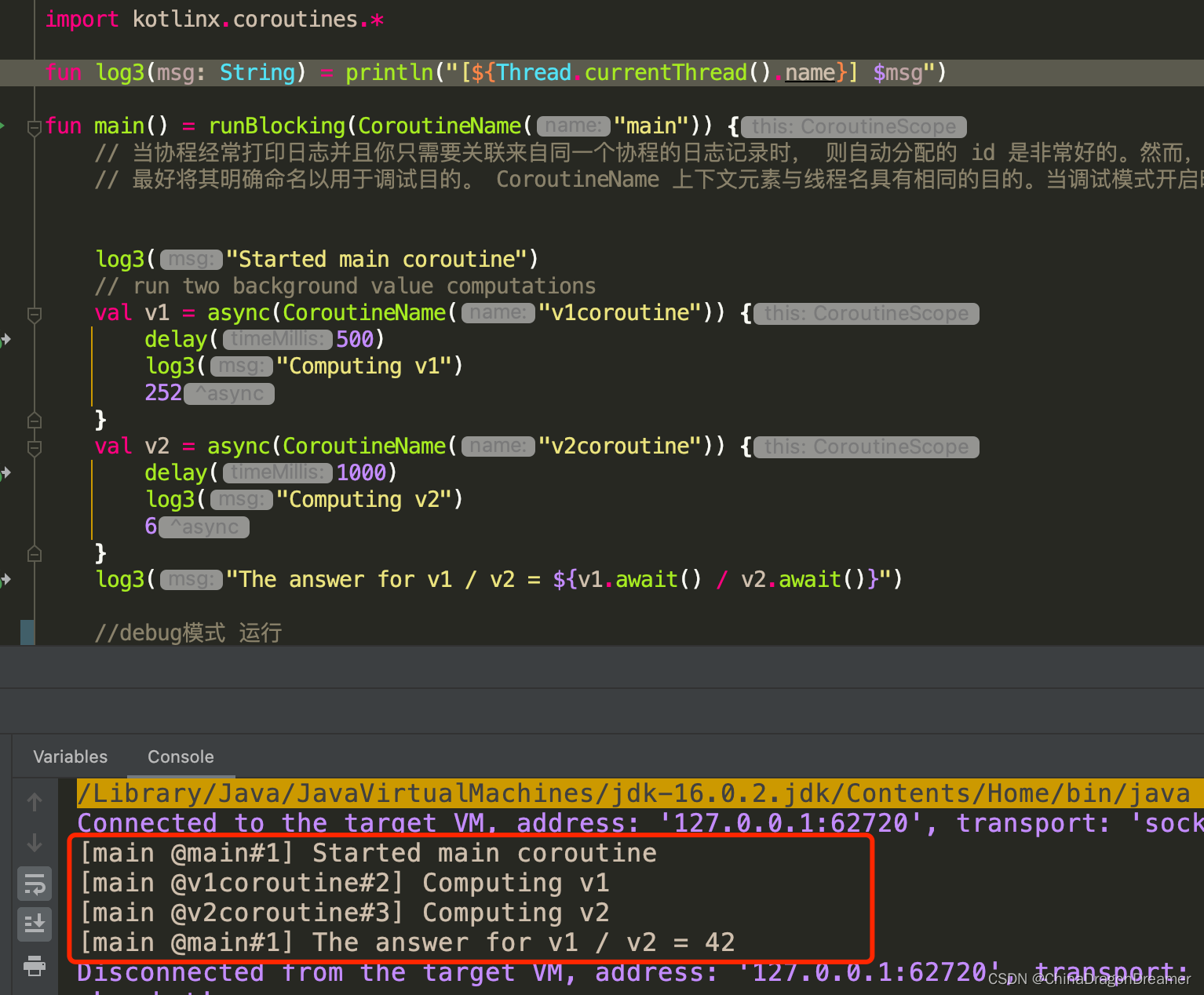
组合上下文中的元素
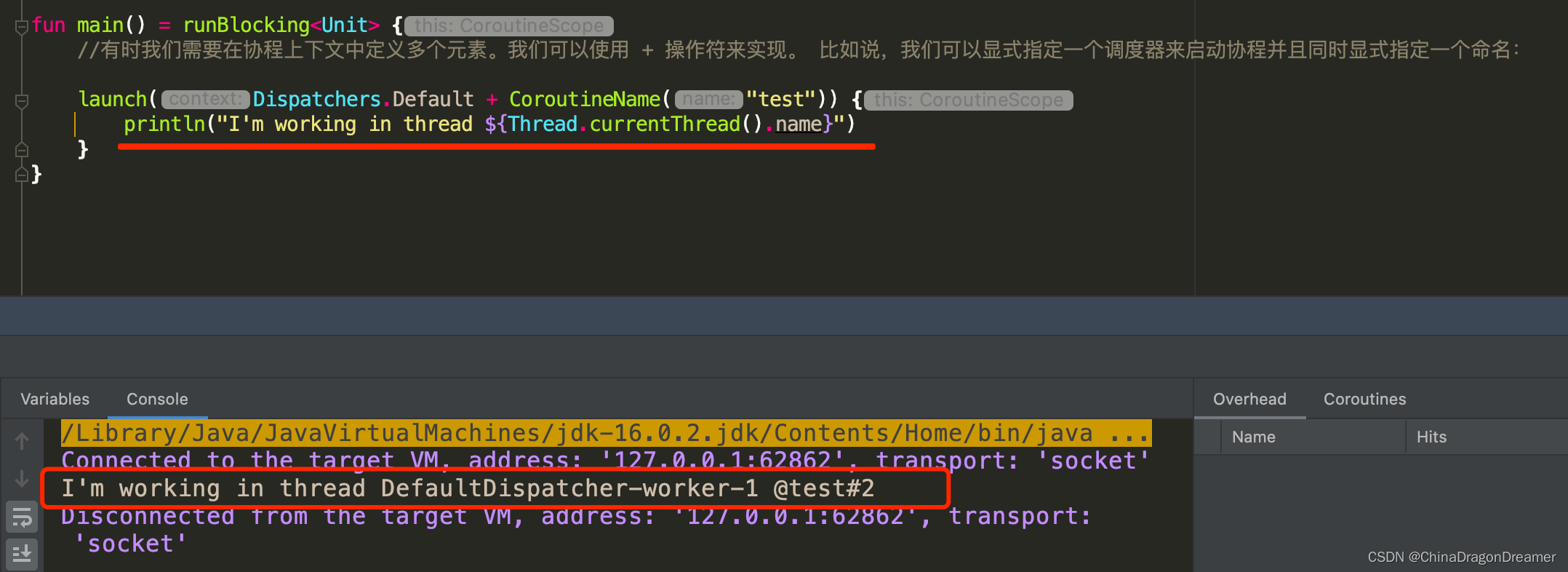
有时我们需要在协程上下文中定义多个元素。我们可以使用 + 操作符来实现。 比如说,我们可以显式指定一个调度器来启动协程并且同时显式指定一个命名:
使用 -Dkotlinx.coroutines.debug JVM 参数运行下面的代码
import kotlinx.coroutines.*
fun main() = runBlocking<Unit> {
//有时我们需要在协程上下文中定义多个元素。我们可以使用 + 操作符来实现。 比如说,我们可以显式指定一个调度器来启动协程并且同时显式指定一个命名:
launch(Dispatchers.Default + CoroutineName("test")) {
println("I'm working in thread ${Thread.currentThread().name}")
}
}
Debug模式运行结果
协程作用域
让我们将关于上下文,子协程以及作业的知识综合在一起。假设我们的应用程序拥有一个具有生命周期的对象,但这个对象并不是一个协程。举例来说,我们编写了一个 Android 应用程序并在 Android 的 activity 上下文中启动了一组协程来使用异步操作拉取并更新数据以及执行动画等等。所有这些协程必须在这个 activity 销毁的时候取消以避免内存泄漏。当然,我们也可以手动操作上下文与作业,以结合 activity 的生命周期与它的协程,但是 kotlinx.coroutines 提供了一个封装:CoroutineScope 的抽象。 你应该已经熟悉了协程作用域,因为所有的协程构建器都声明为在它之上的扩展。
我们通过创建一个 CoroutineScope 实例来管理协程的生命周期,并使它与 activity 的生命周期相关联。CoroutineScope 可以通过 CoroutineScope() 创建或者通过MainScope() 工厂函数。前者创建了一个通用作用域,而后者为使用 Dispatchers.Main 作为默认调度器的 UI 应用程序 创建作用域:
class CoroutineScopeActivity : AppCompatActivity() {
private val mainScope = CoroutineScope(Dispatchers.Default)
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
}
/*override fun onStart() {
super.onStart()
loadData()
}
fun loadData() {
doSomething()
}*/
//现在,我们可以使用定义的 scope 在这个 Activity 的作用域内启动协程。 对于该示例,我们启动了十个协程,它们会延迟不同的时间:
fun doSomething() {
// 在示例中启动了 10 个协程,且每个都工作了不同的时长
repeat(10) {i ->
mainScope.launch {
delay((i +1 )*200L)// 延迟 200 毫秒、400 毫秒、600 毫秒等等不同的时间
println("Coroutine $i is done")
}
}
}
fun destroy() {
mainScope.cancel()
}
override fun onDestroy() {
super.onDestroy()
mainScope.cancel()
}
}
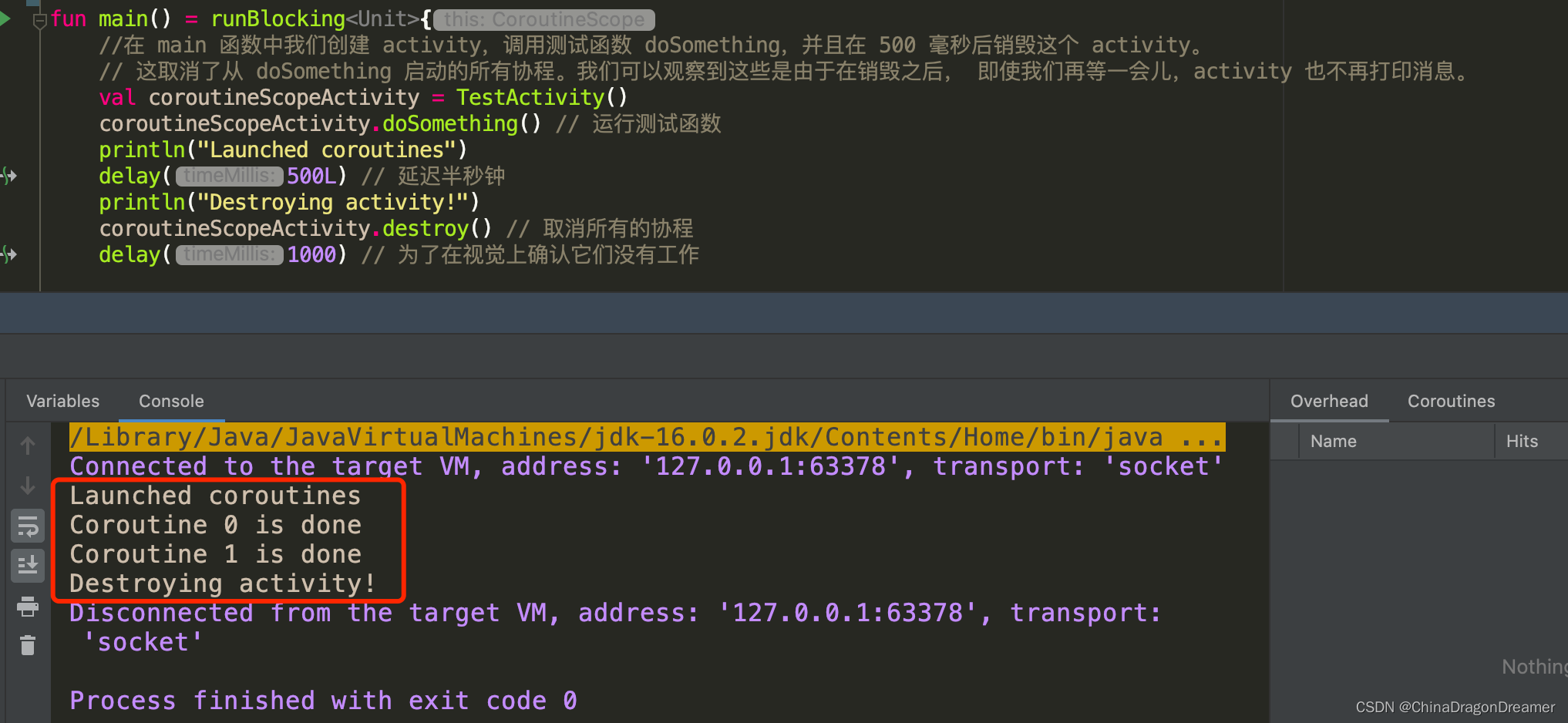
在 main 函数中我们创建 activity,调用测试函数 doSomething,并且在 500 毫秒后销毁这个 activity。
这取消了从 doSomething 启动的所有协程。我们可以观察到这些是由于在销毁之后, 即使我们再等一会儿,activity 也不再打印消息。
fun main() = runBlocking<Unit>{
val coroutineScopeActivity = TestActivity()
coroutineScopeActivity.doSomething() // 运行测试函数
println("Launched coroutines")
delay(500L) // 延迟半秒钟
println("Destroying activity!")
coroutineScopeActivity.destroy() // 取消所有的协程
delay(1000) // 为了在视觉上确认它们没有工作
}
运行结果
可以看到,只有前两个协程打印了消息,而另一个协程在 Activity.destroy() 中单次调用了 job.cancel()。
注意,Android 在所有具有生命周期的实体中都对协程作用域提供了一等的支持。 请查看相关文档。
线程局部数据
有时,能够将一些线程局部数据传递到协程与协程之间是很方便的。 然而,由于它们不受任何特定线程的约束,如果手动完成,可能会导致出现样板代码。
ThreadLocal, asContextElement 扩展函数在这里会充当救兵。它创建了额外的上下文元素, 且保留给定 ThreadLocal 的值,并在每次协程切换其上下文时恢复它。
它很容易在下面的代码中演示:
使用 -Dkotlinx.coroutines.debug JVM 参数运行下面的代码
import kotlinx.coroutines.*
val threadLocal = ThreadLocal<String?>() // declare thread-local variable
fun main() = runBlocking<Unit> {
threadLocal.set("main")
println("Pre-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
val job = launch(Dispatchers.Default + threadLocal.asContextElement(value = "launch")) {
println("Launch start, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
yield()
println("After yield, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
}
job.join()
println("Post-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
}
在这个例子中我们使用 Dispatchers.Default 在后台线程池中启动了一个新的协程,所以它工作在线程池中的不同线程中,但它仍然具有线程局部变量的值, 我们指定使用 threadLocal.asContextElement(value = “launch”), 无论协程执行在哪个线程中都是没有问题的。
debug模式运行结果

这很容易忘记去设置相应的上下文元素。如果运行协程的线程不同, 在协程中访问的线程局部变量则可能会产生意外的值。 为了避免这种情况,建议使用 ensurePresent 方法并且在不正确的使用时快速失败。
ThreadLocal 具有一流的支持,可以与任何 kotlinx.coroutines 提供的原语一起使用。 但它有一个关键限制,即:当一个线程局部变量变化时,则这个新值不会传播给协程调用者(因为上下文元素无法追踪所有 ThreadLocal 对象访问),并且下次挂起时更新的值将丢失。 使用 withContext 在协程中更新线程局部变量,详见 asContextElement。
另外,一个值可以存储在一个可变的域中,例如 class Counter(var i: Int),是的,反过来, 可以存储在线程局部的变量中。然而,在这个案例中你完全有责任来进行同步可能的对这个可变的域进行的并发的修改。
对于高级的使用,例如,那些在内部使用线程局部传递数据的用于与日志记录 MDC 集成,以及事务上下文或任何其它库,请参见需要实现的 ThreadContextElement 接口的文档。