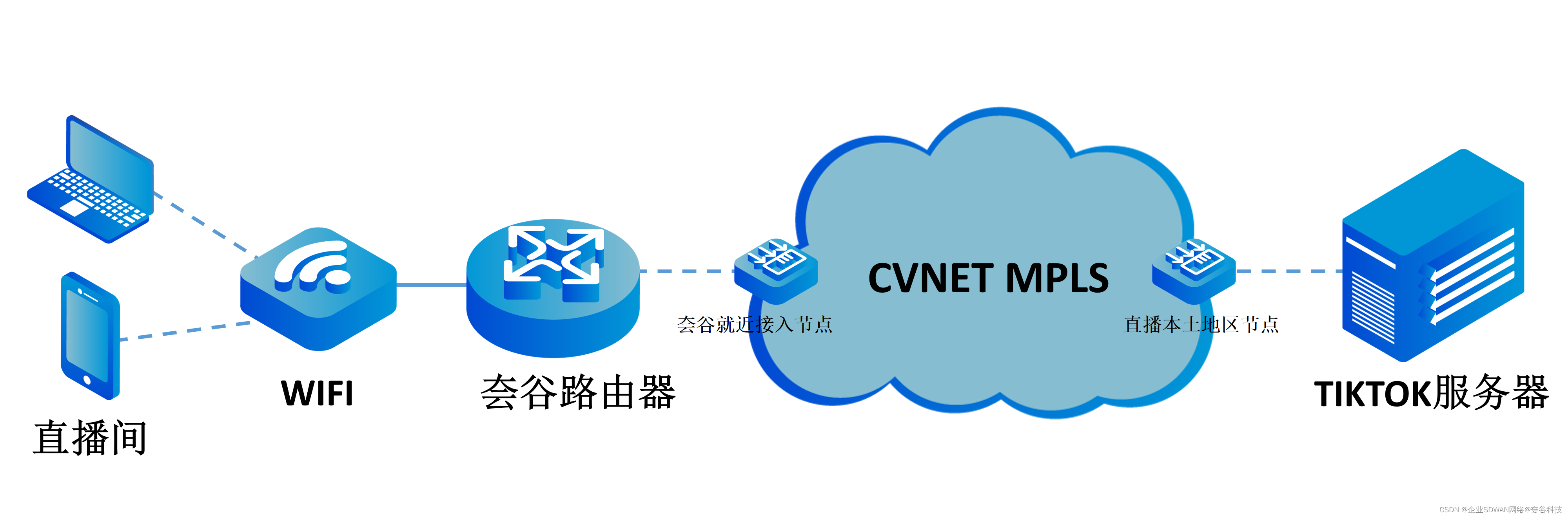
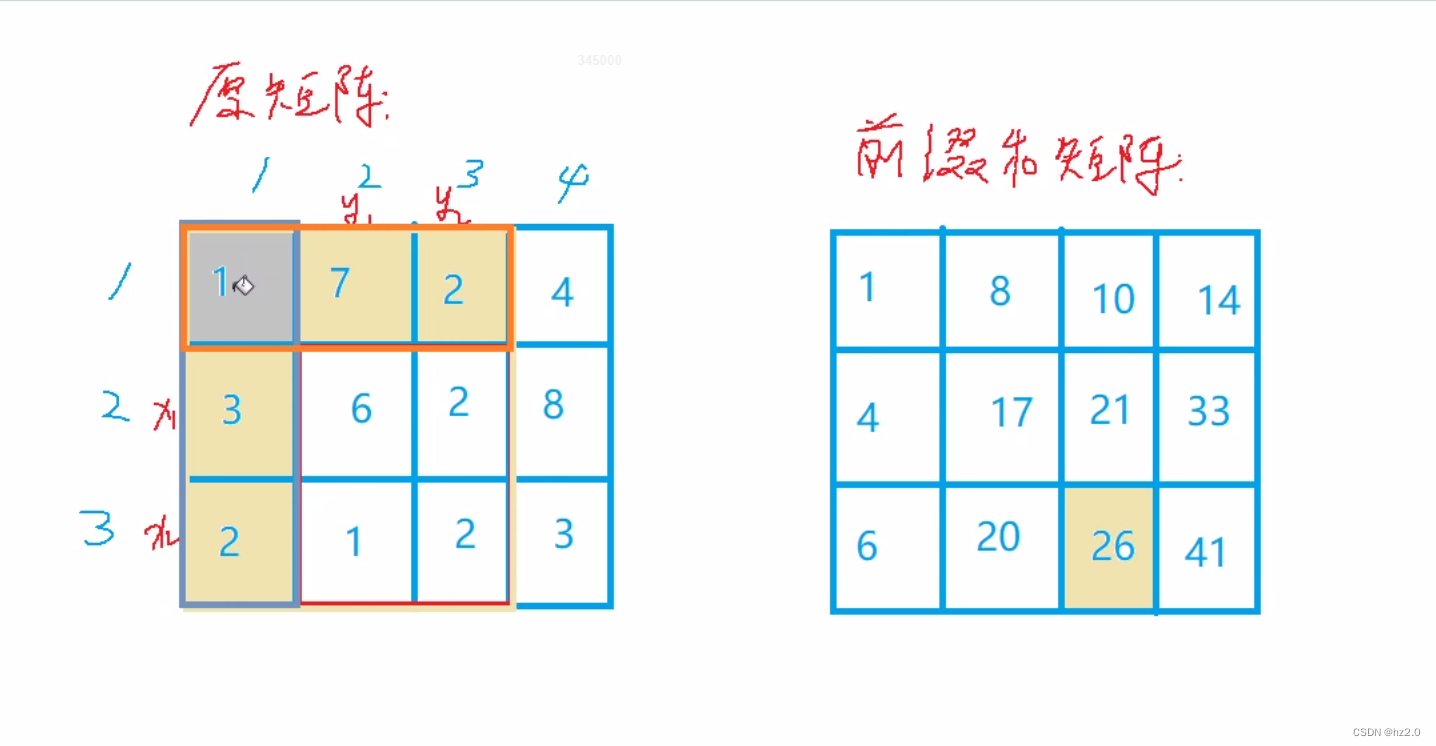
目录
方法一
方法二
需求目的:针对模型训练输入,按照6:2:2的比例进行训练集、测试集和验证集的划分。当前数据量约10万条。如果针对的是记录条数达上百万的数据集,可按照98:1:1的比例进行切分。
方法一:切分训练集和测试集,采用机器学习包sklearn中的train_test_split()函数
方法二:切分训练集、测试集以及验证集,针对dataframe手动切分
方法一
采用Sklearn包中的sklearn.model_selection.train_test_split()函数,该函数功能是将原始数据按照比例切分为训练集和测试集。
python">函数形式:
sklearn.model_selection.train_test_split(*arrays, test_size=None,
train_size=None, random_state=None, shuffle=True, stratify=None)
参数解读:
*arrays:等长的列表、数组或者dataframe等
test_size: 0和1之间,默认0.25
train_size: 0和1之间,默认1
random_state: 传递一个int值,以便在多个函数调用之间产生可复制的输出
shuffle: 拆分前是否进行洗牌
strafity: 是否对数据进行分层
返回结果:
输入序列的train test分割序列例子
python">>>> import numpy as np
>>> from sklearn.model_selection import train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> list(y)
[0, 1, 2, 3, 4]
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.33, random_state=42)
...
>>> X_train
array([[4, 5],
[0, 1],
[6, 7]])
>>> y_train
[2, 0, 3]
>>> X_test
array([[2, 3],
[8, 9]])
>>> y_test
[1, 4]方法二
手动切分,代码如下。输入采用Python的DataFrame,同样输出三个文件。如果需要每次都输入同样的切分数据,可采用random.seed()定义随机数种子。
python">def split_train_test_valid():
# read file
input_path = "E:\\Data\\"
file = "flow.csv"
df_flow = pd.read_csv(input_path + file, header=None, encoding='gbk')
# define the ratios 6:2:2
train_len = int(len(df_flow) * 0.6)
test_len = int(len(df_flow) * 0.2)
# split the dataframe
idx = list(df_flow.index)
random.shuffle(idx) # 将index列表打乱
df_train = df_flow.loc[idx[:train_len]]
df_test = df_flow.loc[idx[train_len:train_len+test_len]]
df_valid = df_flow.loc[idx[train_len+test_len:]] # 剩下的就是valid
# output
df_train.to_csv(input_path+'train.txt', header=False, index=False, sep='\t')
df_test.to_csv(input_path+'test.txt', header=False, index=False, sep='\t')
df_valid.to_csv(input_path+'valid.txt', header=False, index=False, sep='\t')参考资料:https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html