Flink
architecture
job manager is master
task managers are workers
task slot is a unit of resource in cluster, number of slot is equal to number of cores(超线程则slot=2*cores), slot=一组内存+一些线程+共享CPU
when starting a cluster,job manager will allocate a certaion number of slots to each taskManager in cluster,
each slots can run one parallel instance of a task or operator
tasks as a basic unit of work execution physically
each task corresponds to a logical reperesentation of data processiong (entire job chain excution )
a subtask represents some operators physically. which is concrete and excutable with other subtasks run in paralle in the same task slot,Flink will process the excution by chaining compatible oeprators if can be chained in same slot to reduce data shuffling
Subtask 是 Flink 作业中 Operator 的并行实例。每个 Operator 都可以拥有一个或多个 subtask,这些 subtask 是并行执行的,运算符子任务(subtask)的数量是该特定运算符的并行度
subtask scheduling
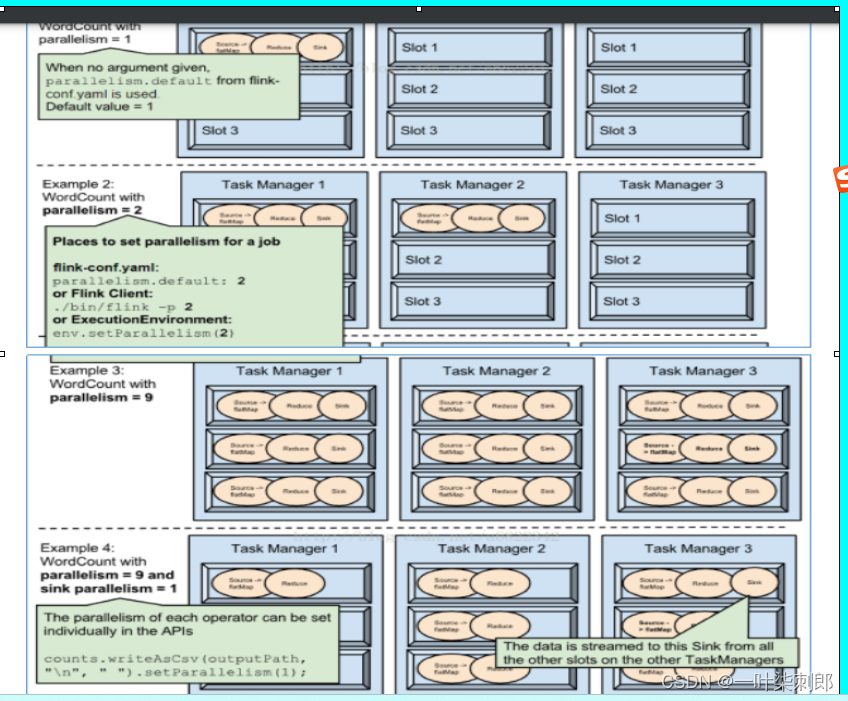
if parallelism is 6, six parallel instances will go across the available task slots.
Flink will process the excution by chaining compatible oeprators if can be chained in same slot to reduce data shuffling
if key by,then all data with same key will be processed in the same slot for accurate state management
**key by group by or window operation need data shuffling(**data movement between nodes)
operator会被chain在同一subtask的情况
(1)手动设置setChainingStrategy(ChainingStrategy.ALWAYS)
.map(x => x * 2)
.filter(x => x > 2)
.setChainingStrategy(ChainingStrategy.ALWAYS)
(2)keyby分区后,相同数据的后续所有操作都在同一个subtask中
keyBy(keySelector).map(…).filter(…) .print();
(3)并行度相同的operators通常可能被chain在一起减少data shuffling
flink Window窗口
在一个无界流中设置起始位置和终止位置,让无界流变成有界流,并且在有界流中进行数据处理,流批转化
- window窗口在无界流中设置起始位置和终止位置的方式可以有两种 ,基于时间或者基于窗口数据量,
- 分组和未分组窗口。自定义窗口
- 时间窗口:
- 滚动窗口: 数据不重复
- 滑动窗口:数据有重复
- 窗口聚合函数:
- 增量聚合:ReduceFunction、AggregateFunction
- 全量聚合 ProcessWindowFunction、WindowFunction属于全量窗口函数