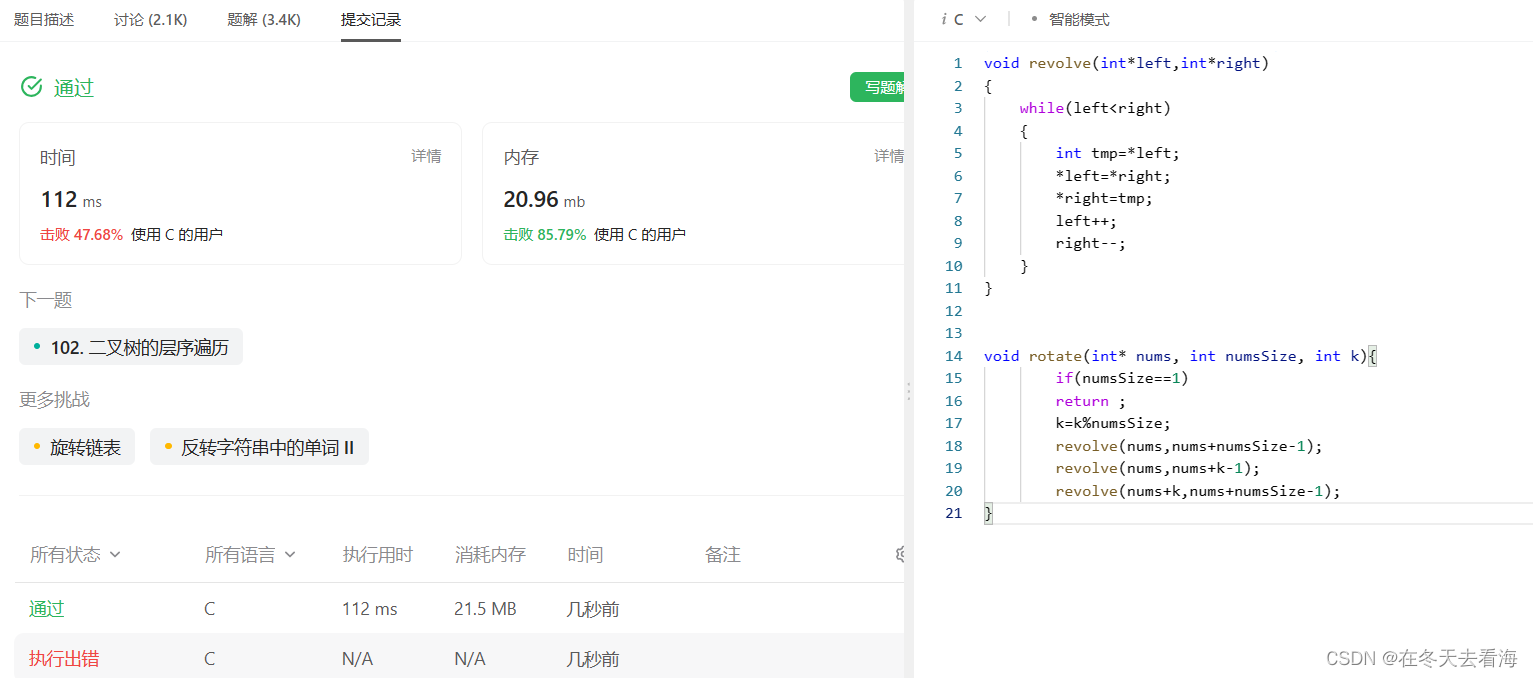
(一)顺序表
1)结构
typedef int SLDateType;
typedef struct SeqList
{
SLDateType* data;
int size;
int capacity;
}SeqList;
SeqList ps = { 0 };
2)函数参数
// 对数据的管理:增删查改
void SeqListInit(SeqList* ps);
void SeqListDestroy(SeqList* ps);
void SeqListPrint(SeqList* ps);
void SeqListPushBack(SeqList* ps, SLDateType x);
void SeqListPushFront(SeqList* ps, SLDateType x);
void SeqListPopFront(SeqList* ps);
void SeqListPopBack(SeqList* ps);
// 顺序表查找
int SeqListFind(SeqList* ps, SLDateType x);
// 顺序表在pos位置插入x
void SeqListInsert(SeqList* ps, int pos, SLDateType x);
// 顺序表删除pos位置的值
void SeqListErase(SeqList* ps, int pos); 3)分析
这里我们要实现函数的参数怎么设置,其实是根据我们实际需求来设计的。
我们的需求是:
创建一个结构体SeqList ps ,然后通过结构体 ps 访问 data, 在通过 data指针可以找到我们 malloc 空间的起始地址,我们可以通过这个起始地址控制 malloc 的整块空间,以使我们可以在这块空间上进行增删查改等操作。
当我们创建结构体SeqList ps 时,实际上是在内存栈区开辟了一块空间,这块空间存储着三个变量:*data、size、capacity;又因为data是一个指针变量,它又指向一块malloc在堆区开辟的空间,我们所有的数据都将在这块空间上处理。
如果函数传参,传的不是结构体SeqList ps 的地址的话,而是直接将结构体传给函数,这样就会出错,因为这就是典型的传值调用,此时,函数用的参数只是原变量的临时拷贝。
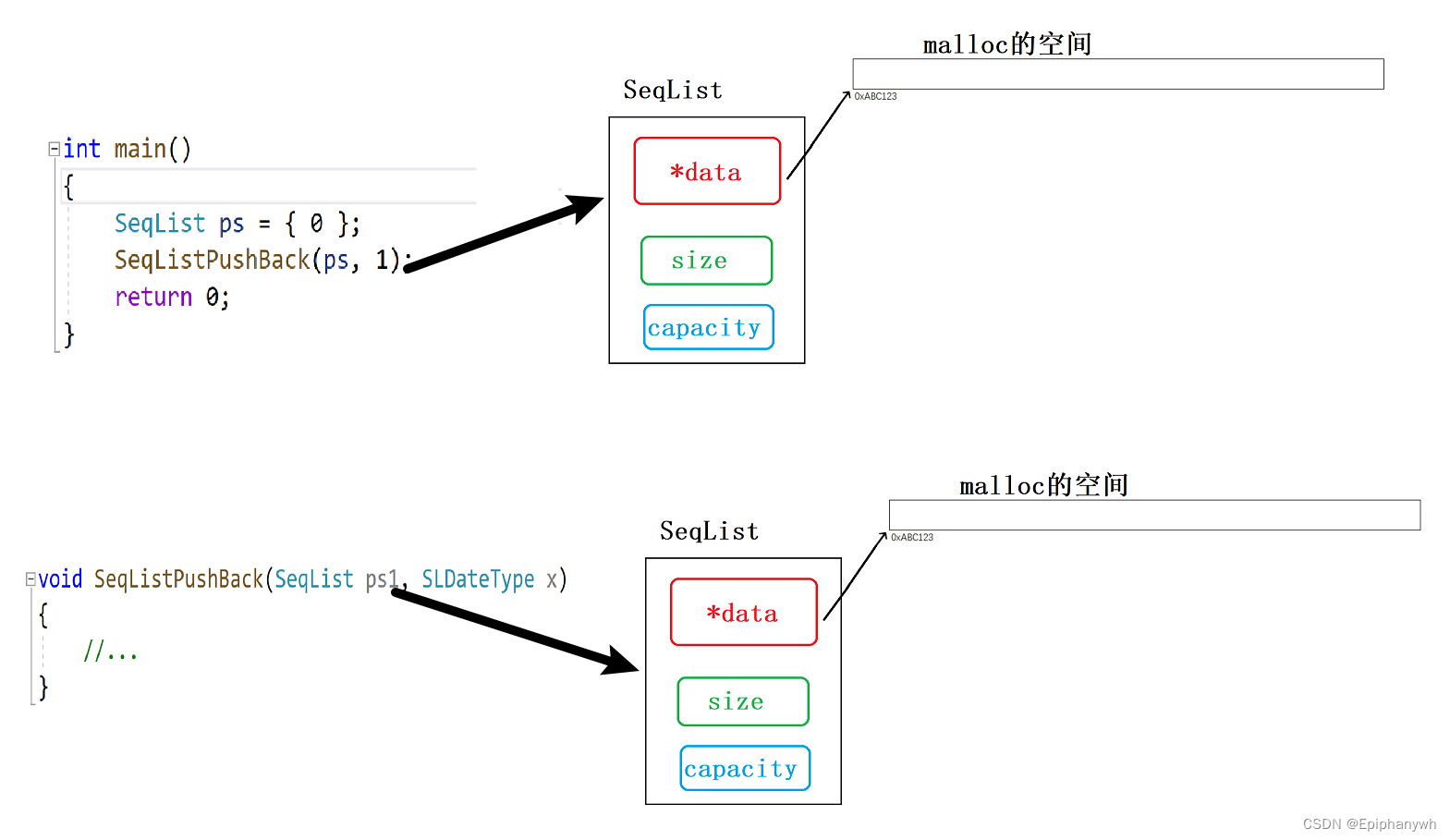
这样我们改变 ps1 ,但 ps 的内容没有改变。要使函数使用的空间和ps相同,就将ps的地址传过去就行了。

所以,函数的参数要传结构体的地址
(二)单向链表:
1)结构
SListNode* phead = NULL;typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;
struct SListNode* next;
}SListNode;2)函数参数
由于实现链表可以用两种结构:带哨兵位头节点和不带哨兵位头节点的两种结构,所以函数的参数类型也会有差异,具体类型详见下列分析。
3)分析
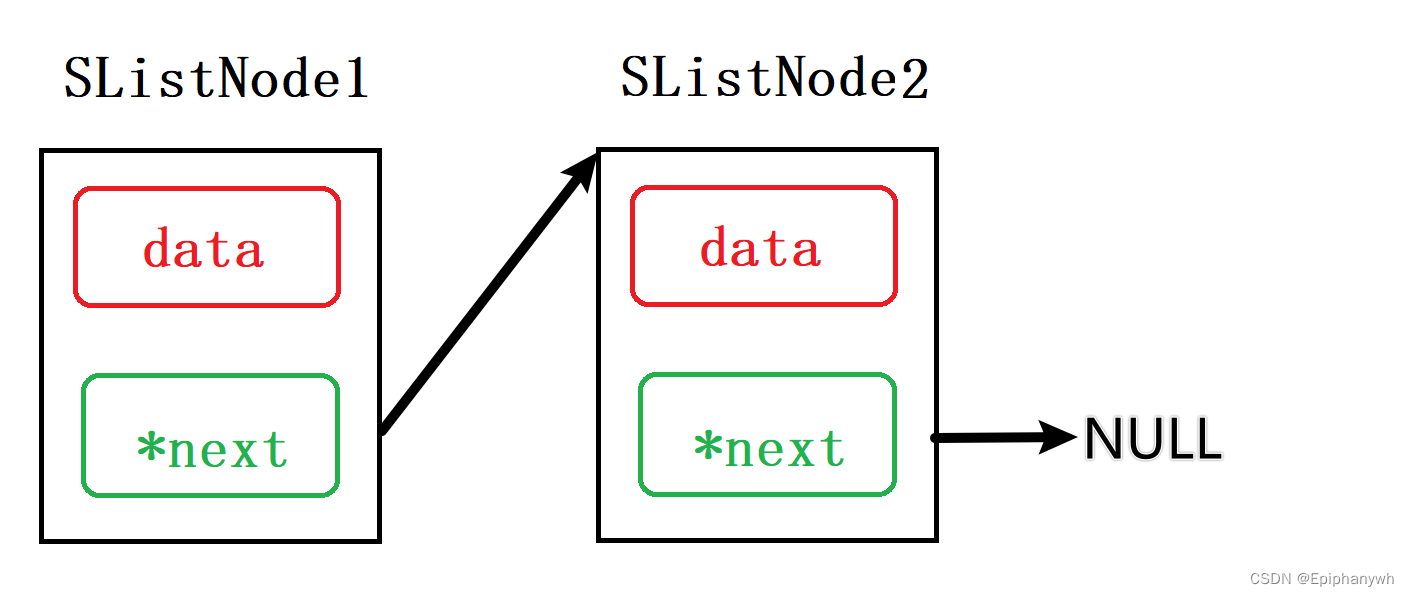
-
将结构体 SListNode1 的地址作为参数(带哨兵位的头节点、一级指针接收)
与上述顺序表相同的道理,我们可以将结构体 SListNode1 的地址作为参数,但是这样就要求SListNode1 必须要在调用函数前创建,其实这样就是将第一个节点作为哨兵位节点,这个节点不存储数据,只是用来作为链表开头的标记。
在链表中,哨兵节点(也称为虚拟节点或标志节点)是一个特殊的节点,通常不存储实际的数据,而是用于简化链表的操作。哨兵节点位于链表的起始或末尾,它不存储有效的数据,但可以帮助在某些情况下简化代码逻辑。
因此我们的代码如下:
void SListPushBack(SListNode* plist, SLTDateType x)
{
// 创建新的节点
SListNode* NewNode = (SListNode*)malloc(sizeof(SListNode));
NewNode->data = x;
NewNode->next = NULL;
// 找到尾节点
SListNode* current = plist;
while (current->next != NULL)
{
current = current->next;
}
current->next = NewNode;
}
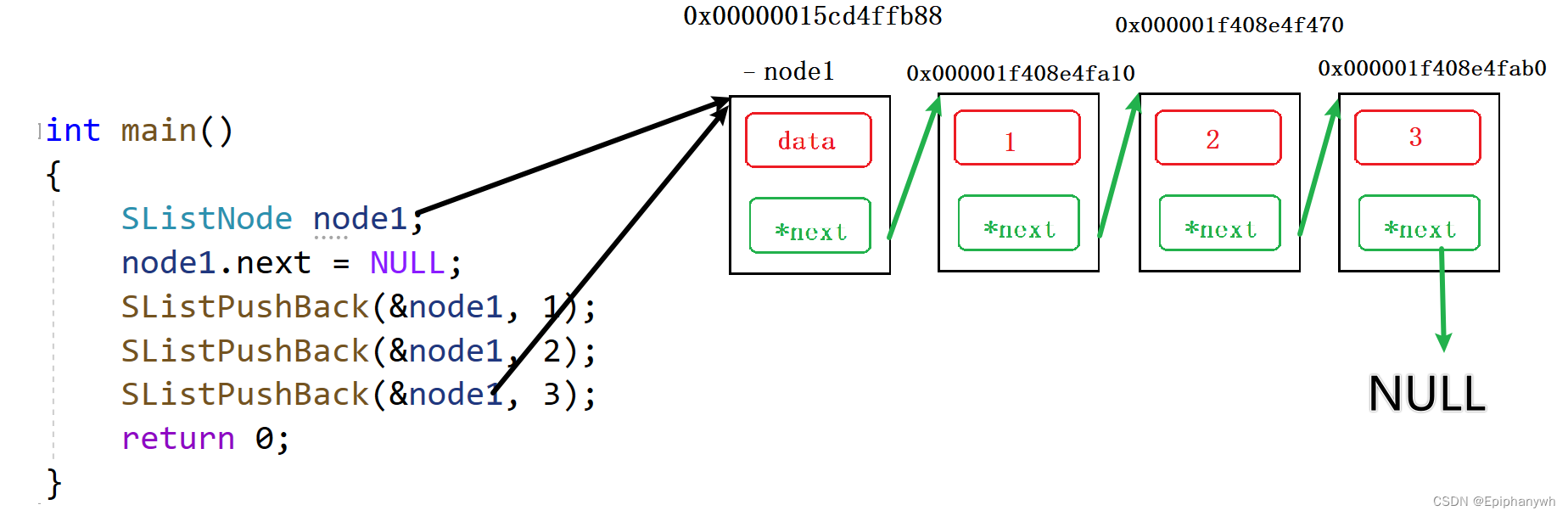
int main()
{
SListNode node1;
SListPushBack(&node1, 1);
SListPushBack(&node1, 2);
SListPushBack(&node1, 3);
return 0;
}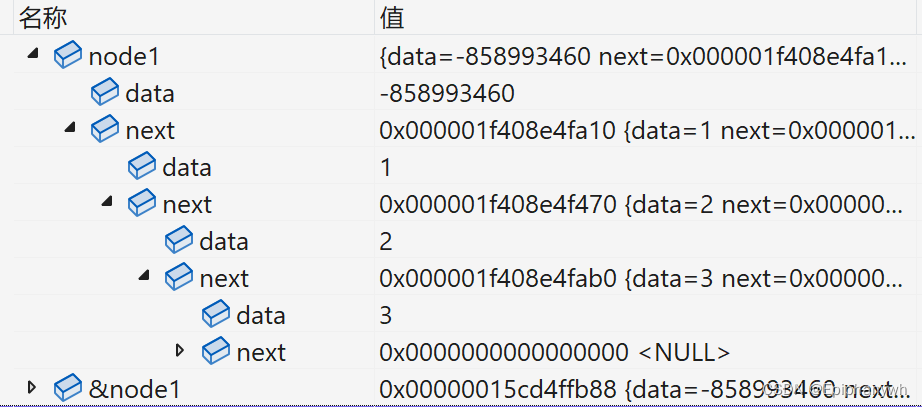
图解:
小结:
使用带哨兵位的头节点时,函数接收节点的类型为:SListNode*
-
用一个指针指向头节点(二级指针接收)
定义一个指针phead ,该指针指向NULL

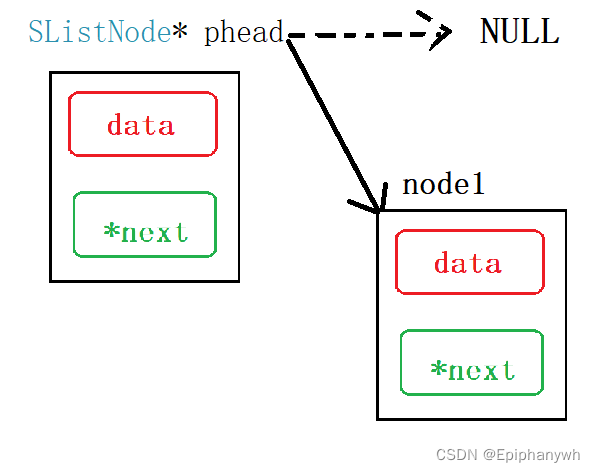
由图中可以看出:head指向NULL,所以显示其内部的变量data、next显示“无法读取内存”;
因为我们想要phead指向头节点,而节点又是 SListNode 类型的,所以phead就需要是 SListNode*类型;
在第一次创建节点时,将phead的指向NULL变为指向头节点,这样就改变了phead:
既然改变了phead,就需要传递phead的地址,想要函数接收phead的地址,就要phead变量类型的指针,phead的变量类型是 SListNode*,所以这个指针就需要是SListNode** 类型的。
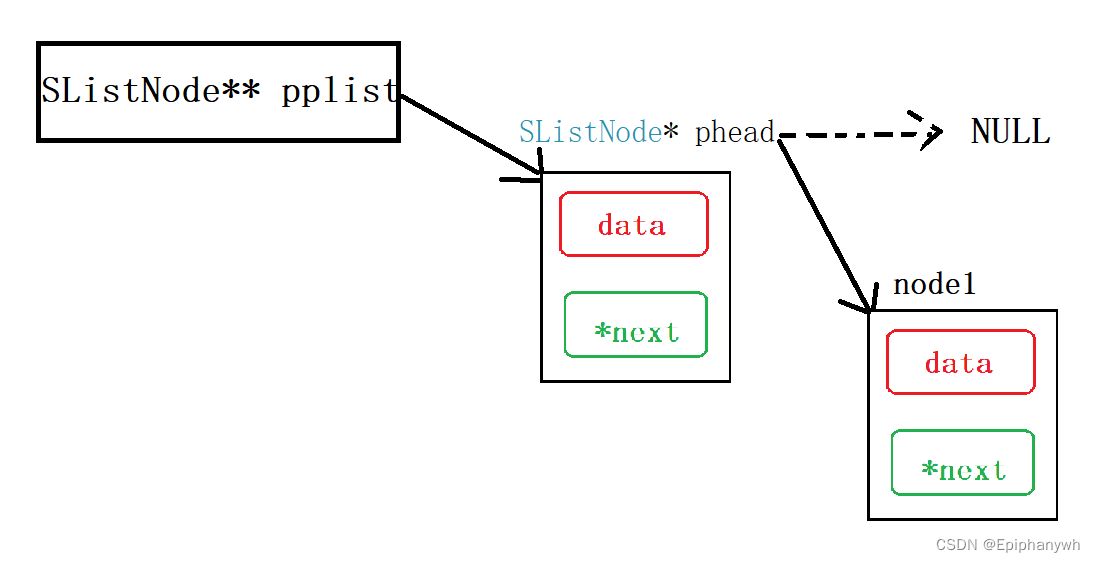
此时phead就不再指向NULL了,而是指向第一个节点(其内部存储的是第一个节点的地址)
通过pplist的解引用就可以找到phead,再通过phead的解引用就可以找到节点的数据域和指针域,进而我们就可以改变节点的数据域,使节点能够存储数据;也可以改变节点的指针域,使各个节点能够连接起来
小结:
不使用使用带哨兵位的头节点,使用指针指向头节点时,函数接收节点的类型为:SListNode**
当然,并不是所有 “用一个指针指向头节点” 的情形都需要使用二级指针来接收,还可以用函数的返回进行传递。
-
利用函数返回值(一级指针接收)
这个结构和上面 “用一个指针指向头节点” 结构和原理是一样的,两者的主要差异就在于这次我们利用了初始化函数的返回值。
先来看一下初始化函数是怎样实现的:
ListNode* ListInit(ListNode* plist)
{
plist = (ListNode*)malloc(sizeof(ListNode));
plist->next = NULL;
return plist;
}
ListNode* head = NULL;
head = ListInit(head);图解:
第一步:

第二步:
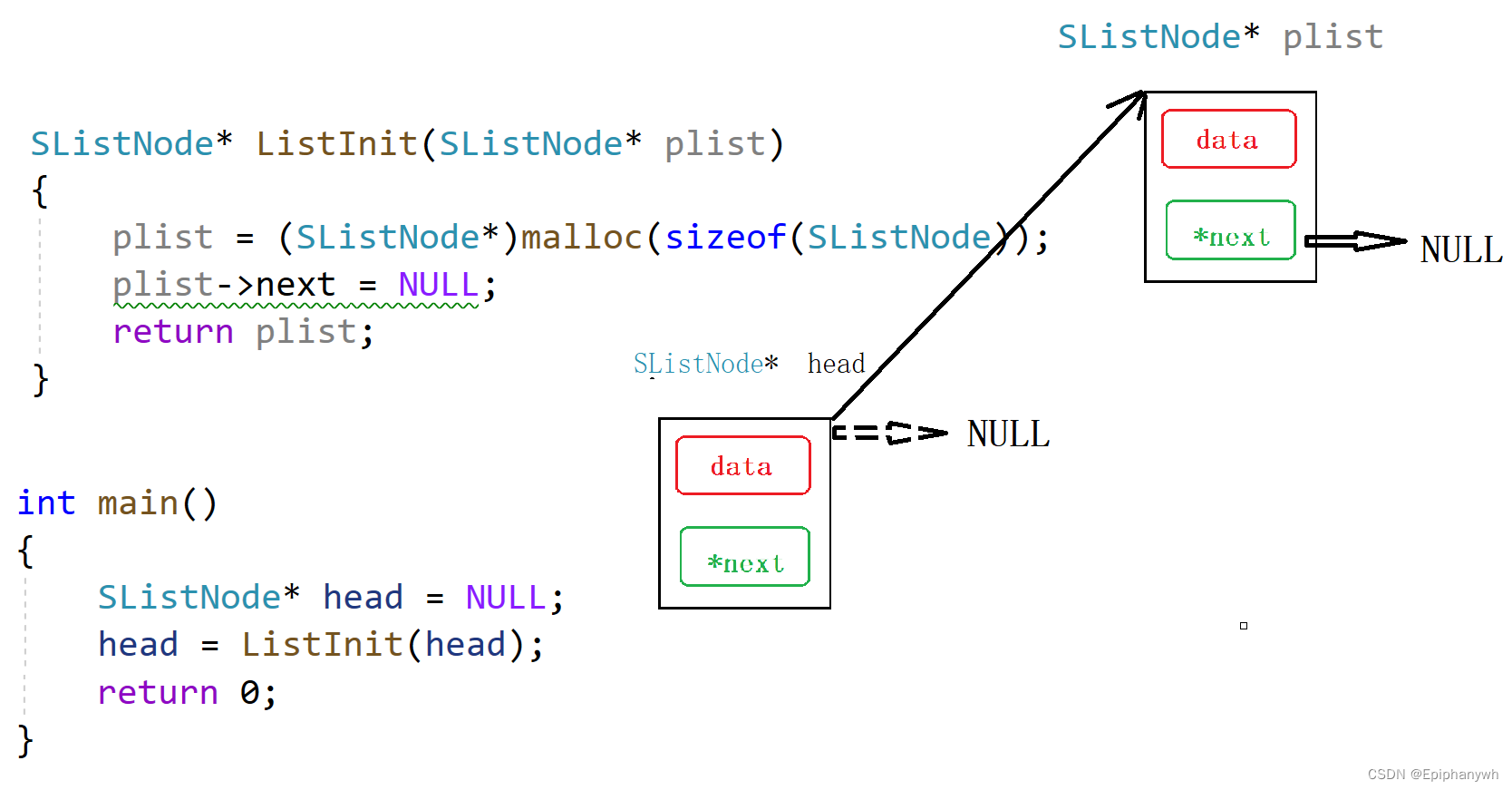
此时 head 就已经指向链表的头节点了,通过head的解引用就可以找到节点的数据域和指针域,进而我们就可以改变节点的数据域,使节点能够存储数据;也可以改变节点的指针域,使各个节点能够连接起来。
我们会发现这种方法根上面 “用一个指针指向头节点” 是一模一样的,其实上面一种方法在改变phead的指向后,其他函数的参数就可以可以是phead了,但是必须要在调用插入函数后,才能这样做。当我们先调用其他函数时,就会出错了,所以为了保险起见,我们统一将二级指针作为函数 的参数。
(三)栈
实现栈可以用数组也可以使用链表,而数组的结构对应的是顺序表的结构,所以对于栈的结构这里我就不在赘述了。
Stack stack;
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top; // 栈顶
int capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
bool StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps);(四)队列
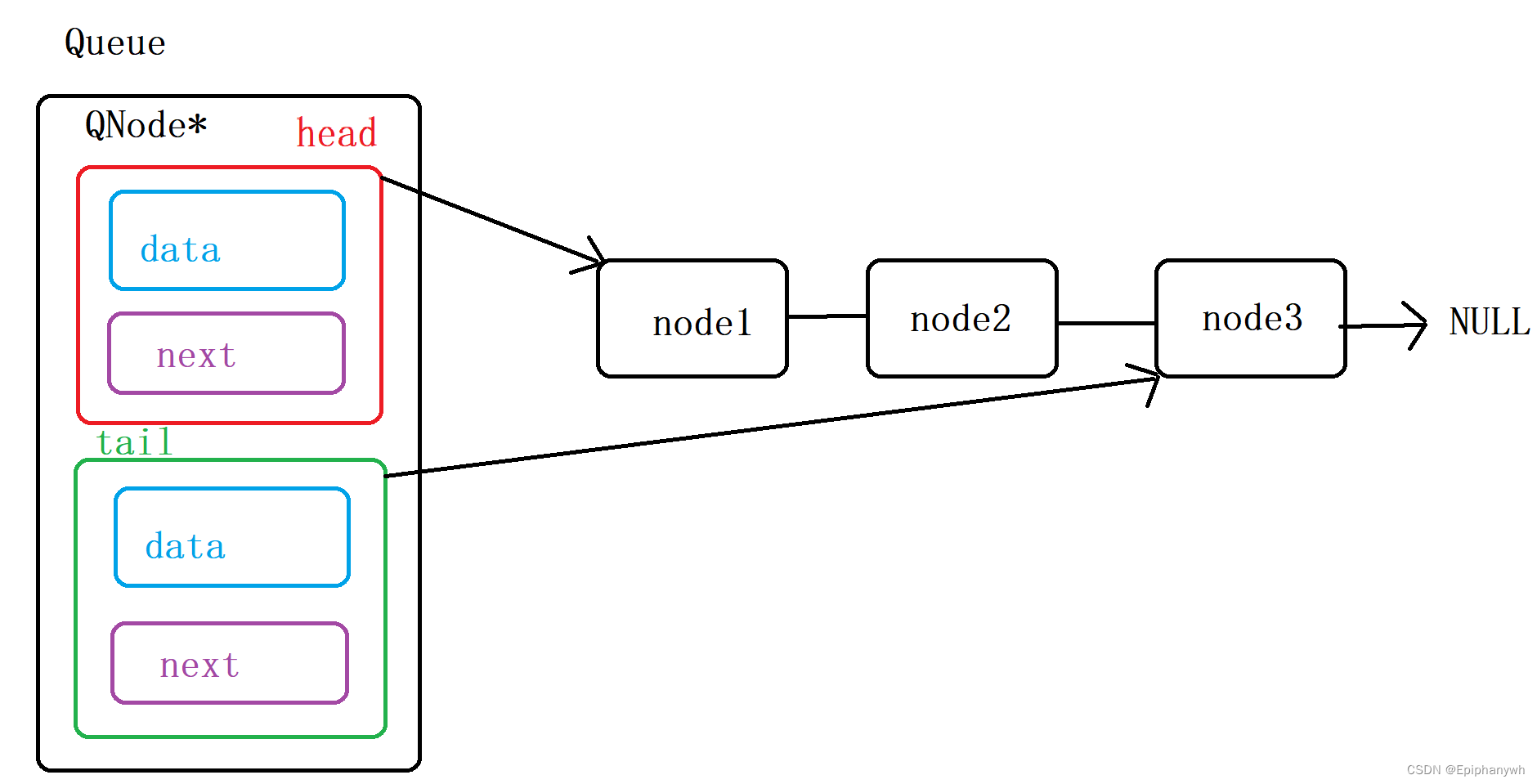
这里利用链表实现队列是比较好的,所以队列的结构对应的是链表的结构。需要注意的是,为了便于尾插和获得队列的末尾元素,我们不仅定义了指向头节点的指针,还定义了指向尾节点的指针,对于这两个指针我们又定义了一个结构体。
Queue q;typedef int QDataType;
//链式结构:表示队列
typedef struct QListNode
{
struct QListNode* next;
QDataType data;
}QNode;
// 队列的结构
typedef struct Queue
{
QNode* head;
QNode* tail;
}Queue;图解:
本次内容到此结束了!如果你觉得这篇博客对你有帮助的话 ,希望你能够给我点个赞,鼓励一下我。感谢感谢……