目录
五、数据清洗
DA24 去掉信息不全的用户
DA25 修补缺失的用户数据
DA26 解决牛客网用户重复的数据
DA27 统一最后刷题日期的格式
六、Json处理
DA28 将用户的json文件转换为表格形式
七、分组聚合
DA29 牛客网的每日练题量
DA30 牛客网用户练习的平均次日留存率
DA31 牛客网每日正确与错误的答题次数
DA32 牛客网答题正误总数
DA33 牛客网连续练习题目3天及以上的用户
DA34 牛客网不同毕业年份的大佬
DA35 不同等级用户语言使用情况
DA36 总人数超过5的等级
八、合并
DA37 统计运动会项目报名人数
DA38 统计运动会项目报名人数(二)
DA39 多报名表的运动项目人数统计
DA40 统计职能部分运动会某项目的报名信息
DA41 运动会各项目报名透视表
DA42 合并用户信息表与用户活跃表
DA43 两份用户信息表格中的查找
九、排序
DA44 某店铺消费最多的前三名用户
DA45 按照等级递增序查看牛客网用户信息
十、函数
DA46 某店铺用户消费特征评分
DA47 筛选某店铺最有价值用户中消费最多前5名
五、数据清洗
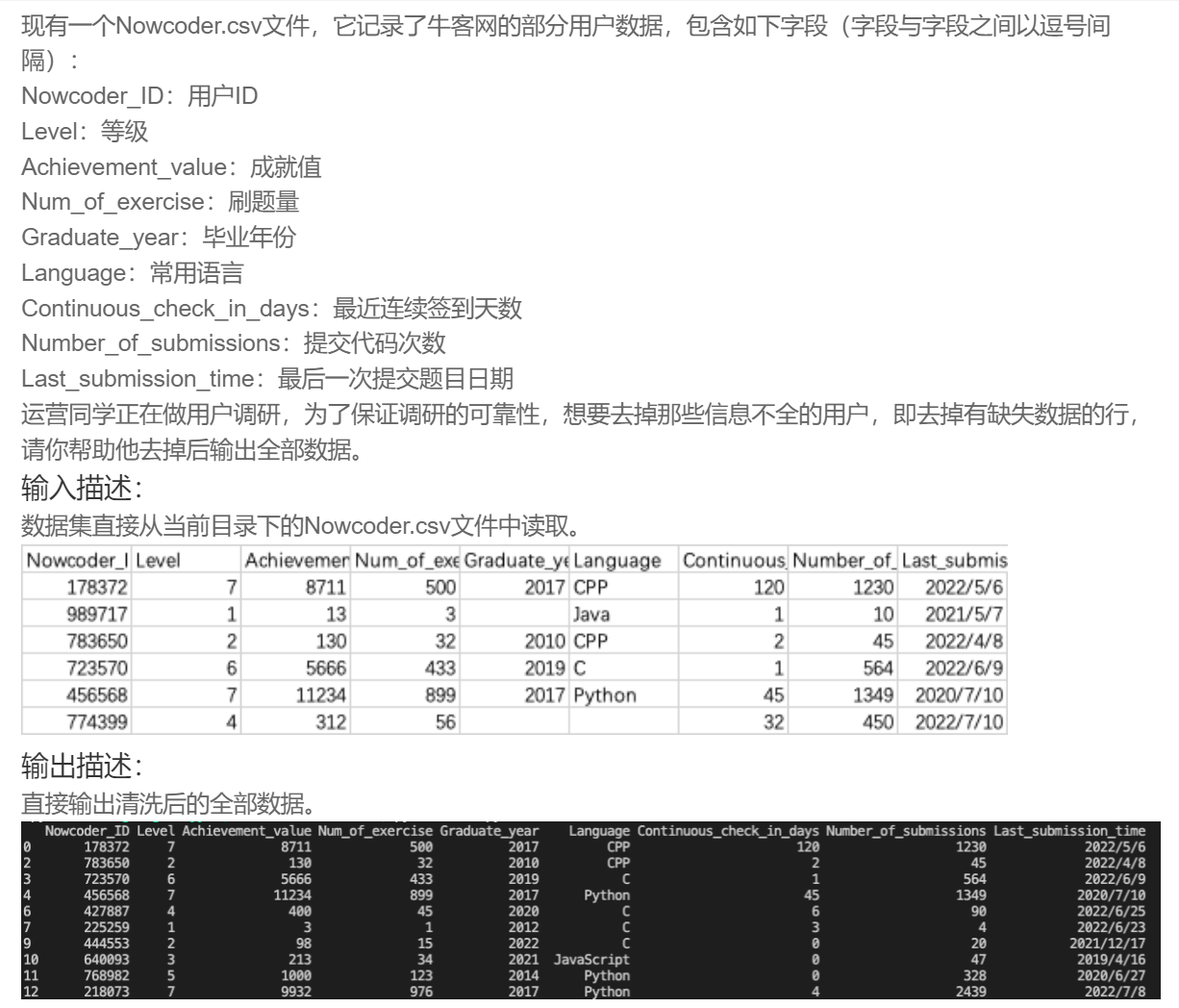
DA24 去掉信息不全的用户
dropna()用法:
DataFrme.dropna(axis=0,how=’any’,thresh=None,subset=None,inplace=False)
参数:
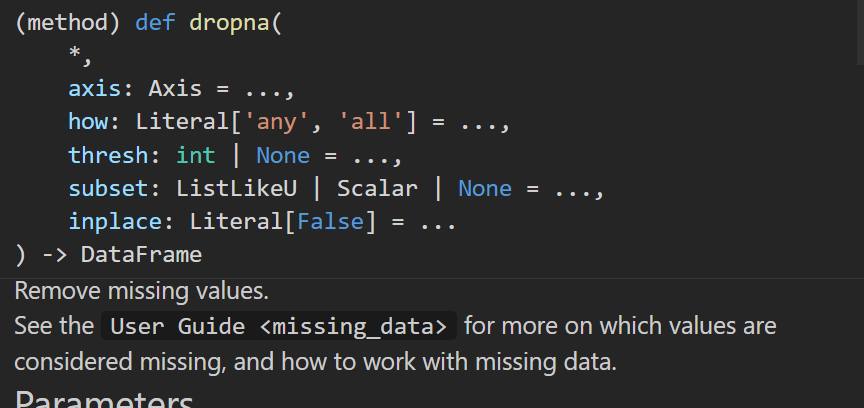
axis: 默认axis=0。0为按行删除,1为按列删除
how: 默认 ‘any’。 ‘any’指带缺失值的所有行/列; 'all’指清除一整行/列都是缺失值的行/列
thresh: int,保留含有int个非nan值的行
subset: 删除特定列中包含缺失值的行或列
inplace: 默认False,即筛选后的数据存为副本,True表示直接在原数据上更改。
python">import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',', dtype=object)
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
print(Nowcoder.dropna())DA25 修补缺失的用户数据
python">import pandas as pd
df = pd.read_csv('Nowcoder.csv', sep=',')
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
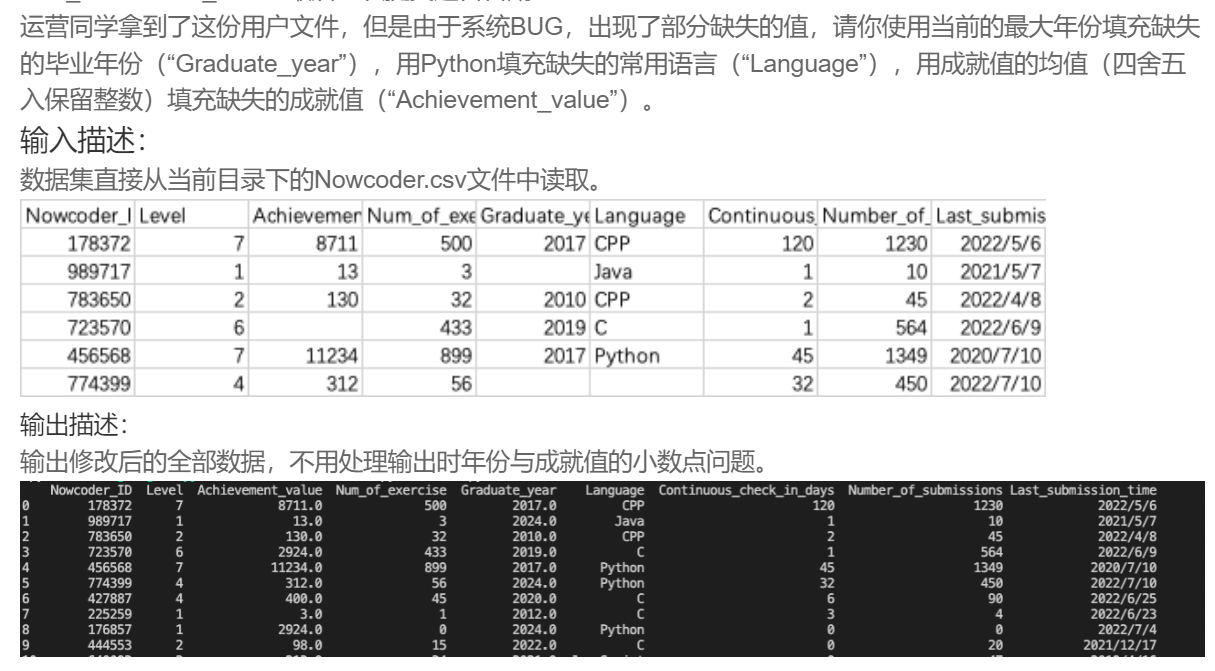
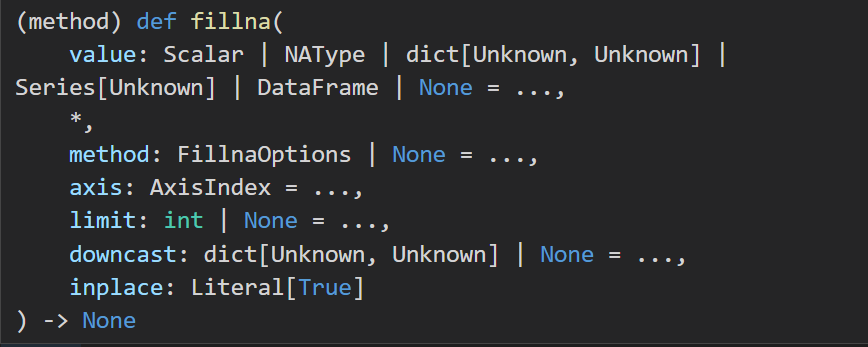
df['Graduate_year'].fillna(df['Graduate_year'].max(),inplace=True)
df['Language'].fillna('Python',inplace=True)
df['Achievement_value'].fillna(int(df['Achievement_value'].mean()),inplace=True)
print(df)DA26 解决牛客网用户重复的数据
python">import pandas as pd
df = pd.read_csv('Nowcoder.csv', sep=',')
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
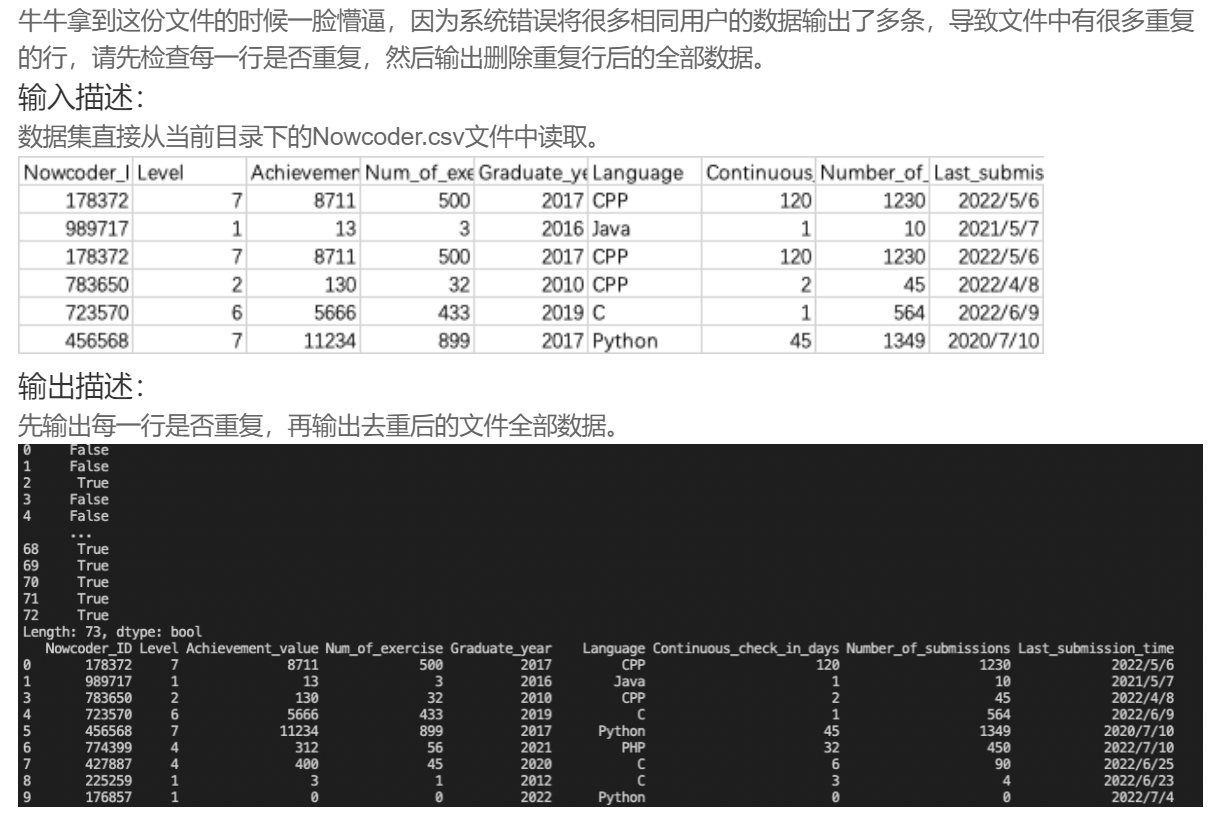
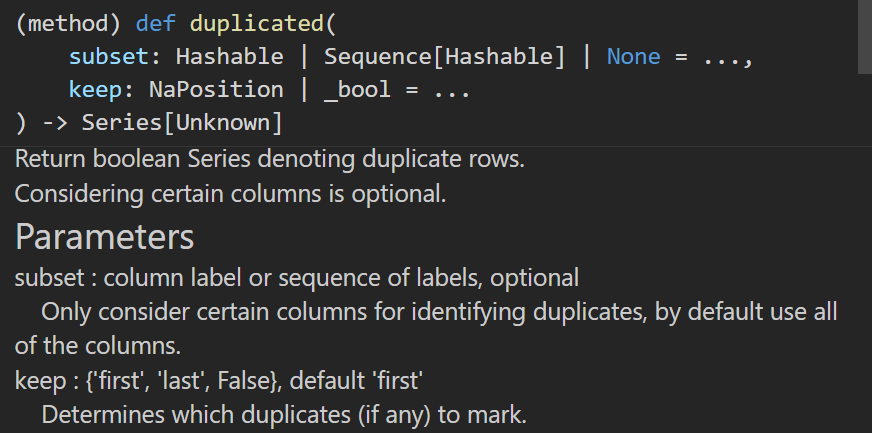
print(df.duplicated())
print(df.drop_duplicates())DA27 统一最后刷题日期的格式

python">import pandas as pd
df = pd.read_csv('Nowcoder.csv',sep=',',dtype=object)
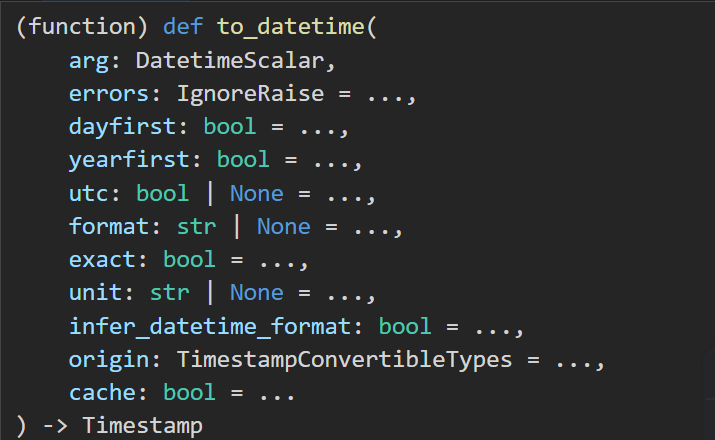
# df['Last_submission_time'] = pd.to_datetime(df["Last_submission_time"],format="%Y-%m-%d")
# 很神奇
df['Last_submission_time'] = pd.to_datetime("2022-01-01")
print(df[['Nowcoder_ID','Level','Last_submission_time']])六、Json处理
DA28 将用户的json文件转换为表格形式
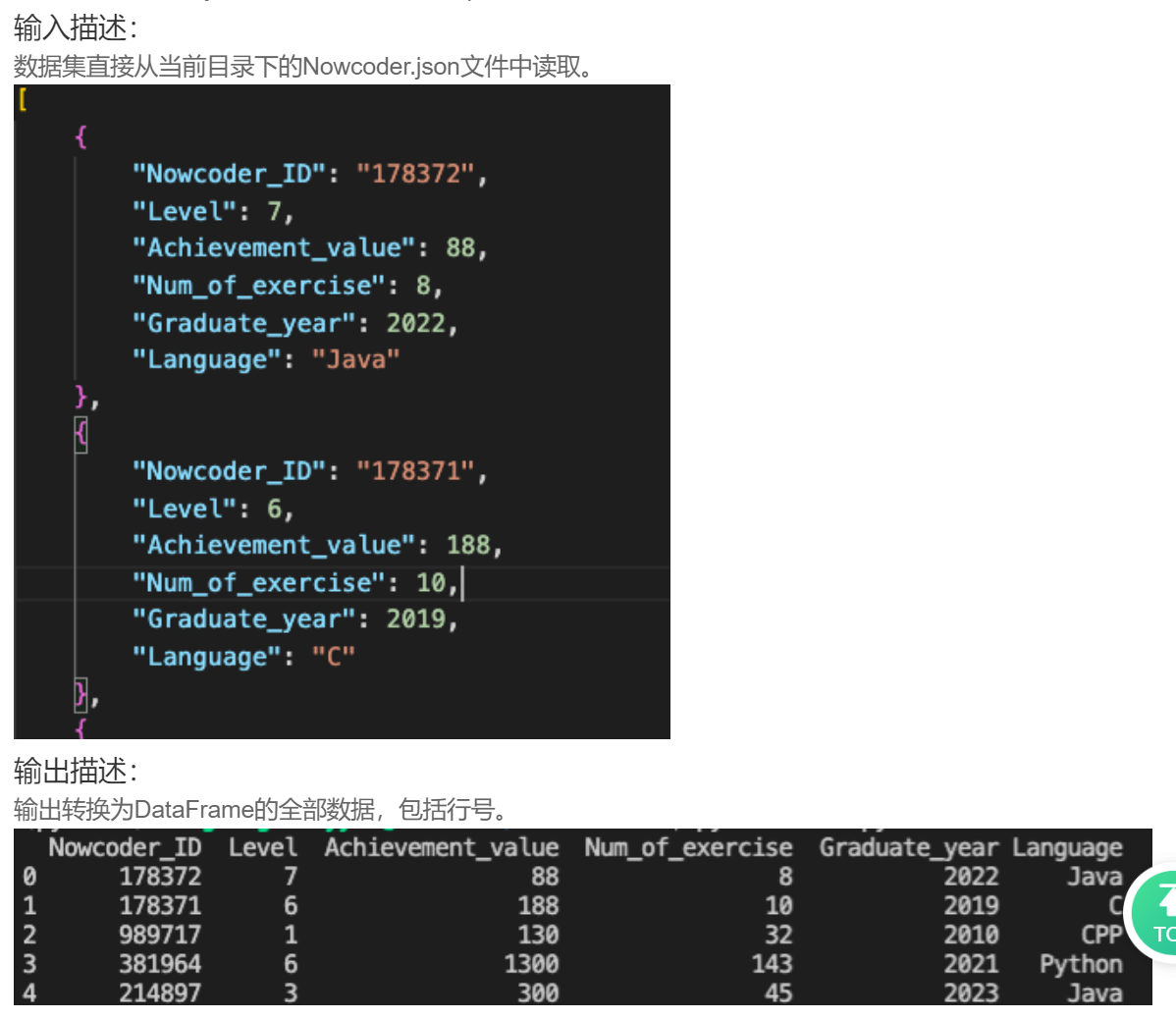
现有一个Nowcoder.json文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Graduate_year:毕业年份
Language:常用语言
如果你读入了这个json文件,能将其转换为pandas的DataFrame格式吗?
python">import pandas as pd
import json
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
with open('Nowcoder.json', 'r') as f:
data = json.loads(f.read())
print(pd.DataFrame(data))
python">df = pd.read_json("Nowcoder.json")
print(df)七、分组聚合
DA29 牛客网的每日练题量

python">import pandas as pd
import datetime as dt
df = pd.read_csv("nowcoder.csv")
# 将date转换为日期格式
df["date"] = pd.to_datetime(df["date"]).dt.date
# 筛选统计区间 2021年12月
data = df[(df["date"] >= dt.date(2021, 12, 1)) & (df["date"] <= dt.date(2021, 12, 31))]
# 使用 groupby 按照 date 分组,聚合函数 count 统计题目数量
daily_num = data.groupby("date")["question_id"].count()
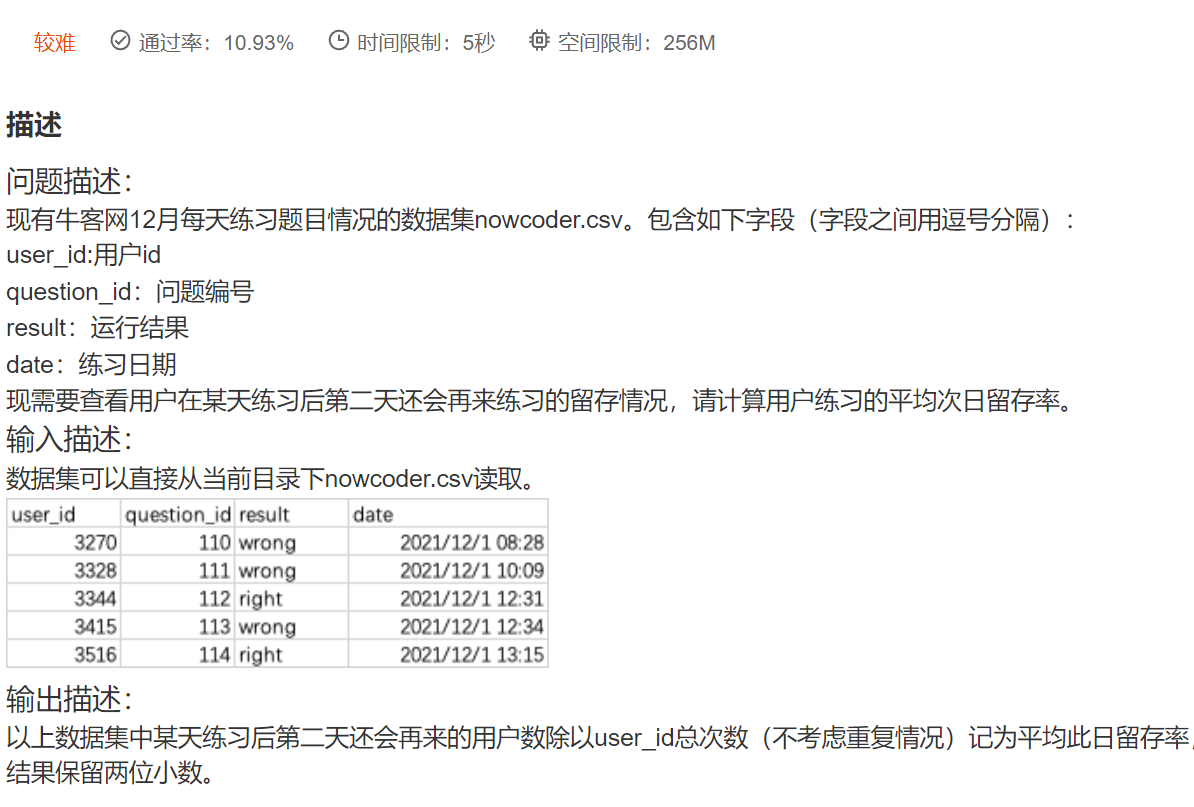
print(daily_num)DA30 牛客网用户练习的平均次日留存率
这题有点难 没看懂
python">import pandas as pd
from datetime import timedelta
nowcoder = pd.read_csv('nowcoder.csv')
#总数
total_id = nowcoder['user_id'].count()
b = pd.merge(nowcoder,nowcoder,on = 'user_id')
#merge之后的列名:user_id,question_id_x,result_x,date_x,question_id_y,result_y,date_y
#是自动区分xy的
b['date_x'] = pd.to_datetime(b.date_x).dt.date
# to_datetime默认有时间精度,.dt.date去掉分钟,得到日期列表2021-12-1
b['date_y'] = pd.to_datetime(b.date_y).dt.date
b['differ'] = b.date_y - b.date_x
sum_diff = b[b.differ == '1 days'].differ.count()
res = round(sum_diff/total_id,2)
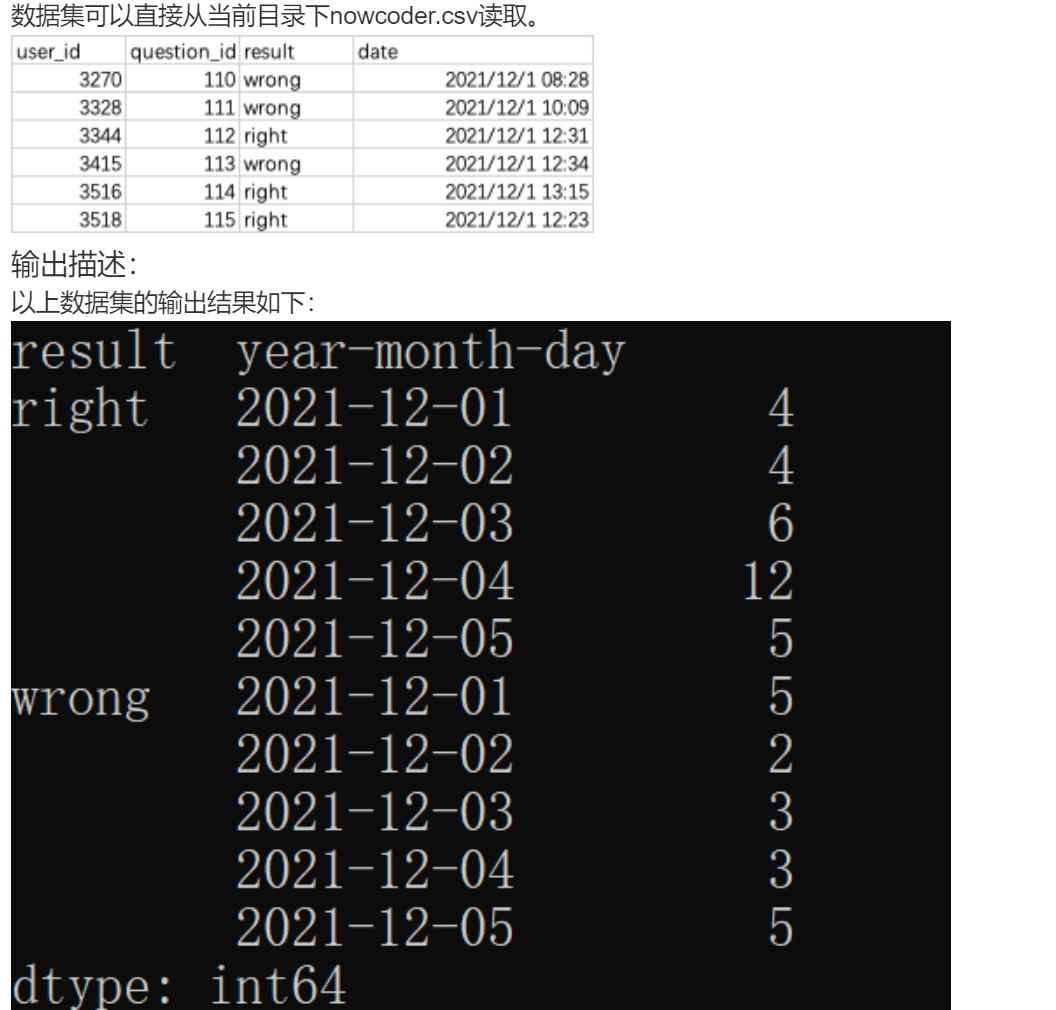
print(res)DA31 牛客网每日正确与错误的答题次数
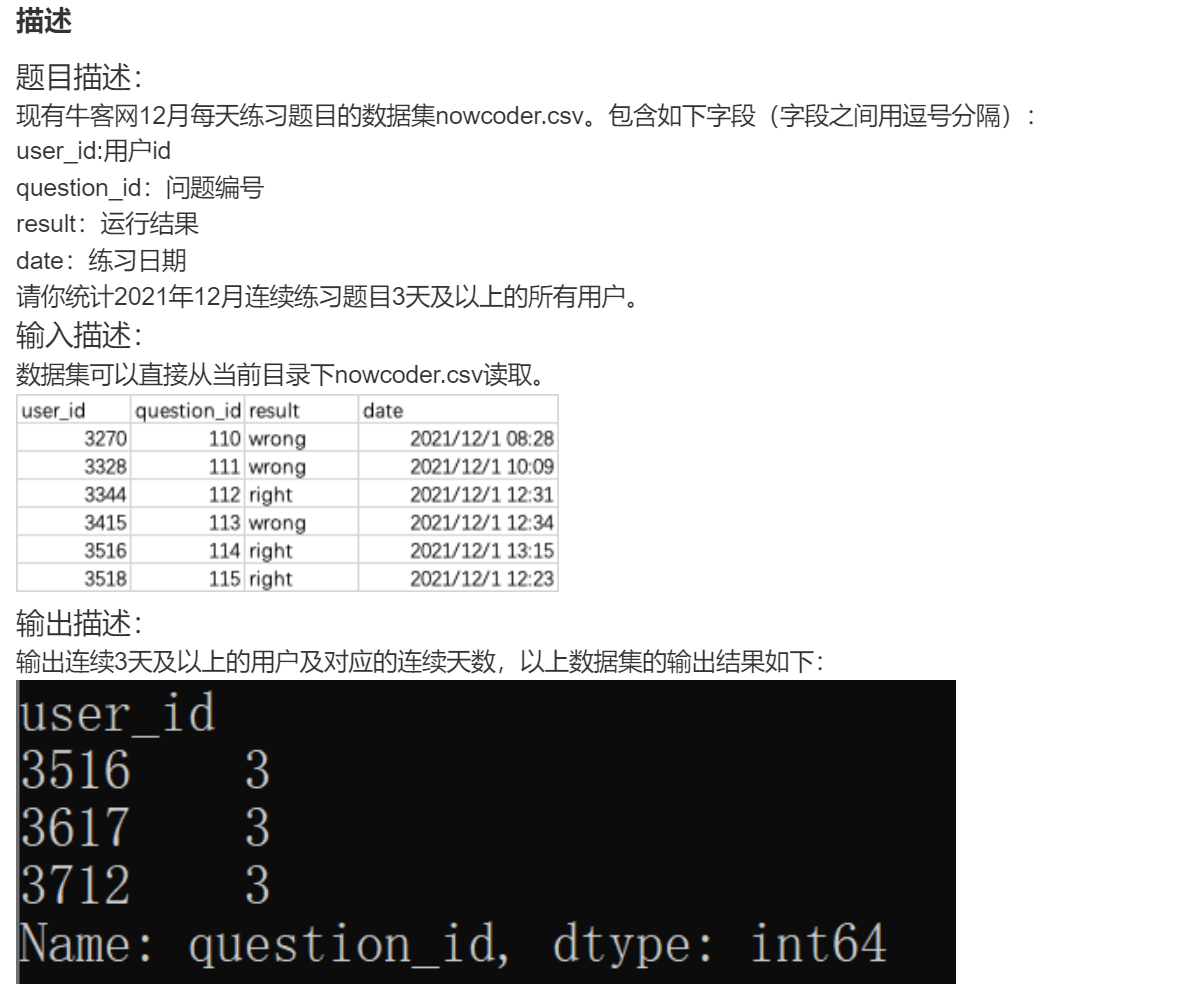
现有牛客网12月每天练习题目的数据集nowcoder.csv。包含如下字段(字段之间用逗号分隔):
- user_id:用户id
- question_id:问题编号
- result:运行结果
- date:练习日期
请你统计2021年12月答题结果正确和错误的前提下每天的答题次数。
python">import pandas as pd
nowcoder = pd.read_csv('nowcoder.csv')
nowcoder['year-month-day'] = pd.to_datetime(nowcoder['date']).dt.date
print(nowcoder.groupby(['result','year-month-day'])['question_id'].count())DA32 牛客网答题正误总数

python">import pandas as pd
nowcoder = pd.read_csv('nowcoder.csv')
a=nowcoder.groupby("result")
print(a.size())DA33 牛客网连续练习题目3天及以上的用户
这题有点难:
大佬的解答,虽然没通过,但是非常细。
python">import pandas as pd
from datetime import timedelta
nowcoder = pd.read_csv("nowcoder.csv")
# -----N日留存
# 格式化日期年月
nowcoder["date1"] = pd.to_datetime(nowcoder["date"]).dt.strftime("%Y-%m")
# 格式化日期年月日
nowcoder["date2"] = pd.to_datetime(nowcoder["date"]).dt.strftime("%Y%m%d")
# 将年月日换成整型,便于运算
nowcoder["date2"] = nowcoder["date2"].astype("int")
# 将日期加+1,便于后期的连续日期判断
nowcoder["date3"] = nowcoder["date2"].apply(lambda x: x + 1)
# 按要求筛选出满足年月的数据
nowcoder_1 = nowcoder[nowcoder["date1"] == "2021-12"]
# 获取排名-1,最小日期的排名应该是0
nowcoder_1["rk"] = (
nowcoder_1.groupby(by="user_id")
.date2.rank(axis=1, ascending=True, method="dense")
.apply(lambda x: x - 1)
)
# 获取满足连续日数据并去重
nowcoder_2 = pd.merge(
nowcoder_1[["user_id", "date", "date2", "rk"]],
nowcoder_1[["user_id", "date3"]],
left_on=["user_id", "date2"],
right_on=["user_id", "date3"],
).drop_duplicates()
# 连续日期减去排名等于最小日期
nowcoder_2["date4"] = (
nowcoder_2[["date3", "rk"]].apply(lambda x: x[0] - x[1], axis=1).astype("int")
)
# 得出次数+1
DAU = (
nowcoder_2[["user_id", "date4"]]
.groupby(by="user_id")["user_id"]
.count()
.apply(lambda x: x + 1)
)
print(DAU[DAU >= 3])
python">'''
代码已通过,两个要点:
1. 先去掉date的时间,再转为日期格式;
2. 对user_id和答题日期去重。
'''
import pandas as pd
from datetime import timedelta
nowcoder = pd.read_csv('nowcoder.csv')
nowcoder['date'] = pd.to_datetime(nowcoder['date'].str.split(' ', expand=True).iloc[:,0]) # 去掉时间,然后将字符串转为日期格式
df = nowcoder[nowcoder['date'].dt.strftime("%Y-%m") == '2021-12'][['user_id','date']].drop_duplicates() # 筛选12月的数据,只取user_id和答题日期,并去重
df['rk'] = pd.to_timedelta(df.groupby(['user_id'])['date'].rank(),unit='d') # 根据user_id分组,并根据答题日期date排序;将排序转为日期差rk,以天为单位
df['diff'] = df['date']-df['rk'] # 答题日期减去日期差rk,得到diff;同一个用户同一次连续答题,会有一样的diff值
df1 = df.groupby(['user_id','diff']).count() # 得到每个用户每次连续答题的天数
df2 = df1.groupby('user_id')['rk'].max() # 取用户最大连续答题天数
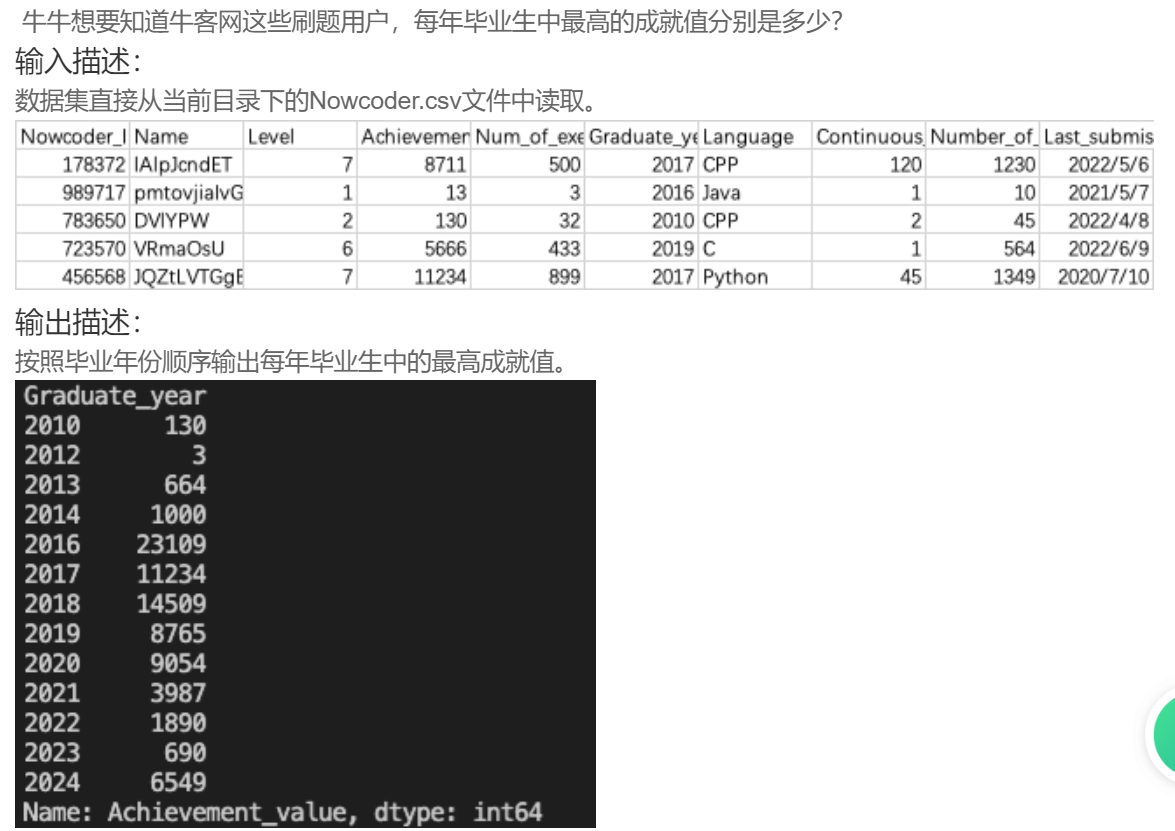
print(df2[df2>=3])DA34 牛客网不同毕业年份的大佬
easy
python">import pandas as pd
df = pd.read_csv("Nowcoder.csv", sep=",")
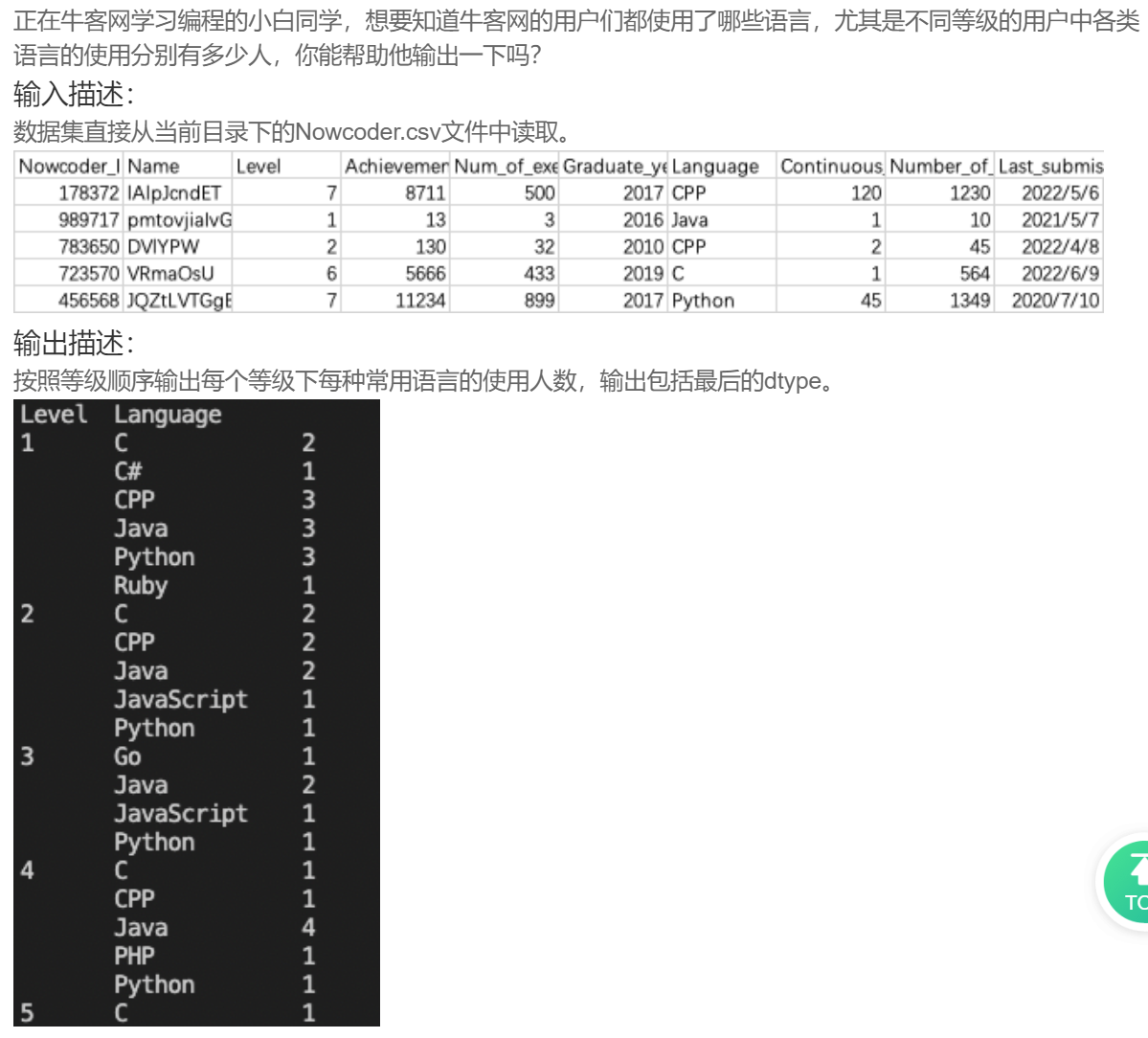
print(df.groupby(["Graduate_year"]).Achievement_value.max())DA35 不同等级用户语言使用情况
easy
python">import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(Nowcoder.groupby(['Level','Language']).Nowcoder_ID.count())DA36 总人数超过5的等级

python">import pandas as pd
df = pd.read_csv('Nowcoder.csv', sep=',')
print(df.groupby(['Level']).Nowcoder_ID.count()>5)
八、合并
DA37 统计运动会项目报名人数


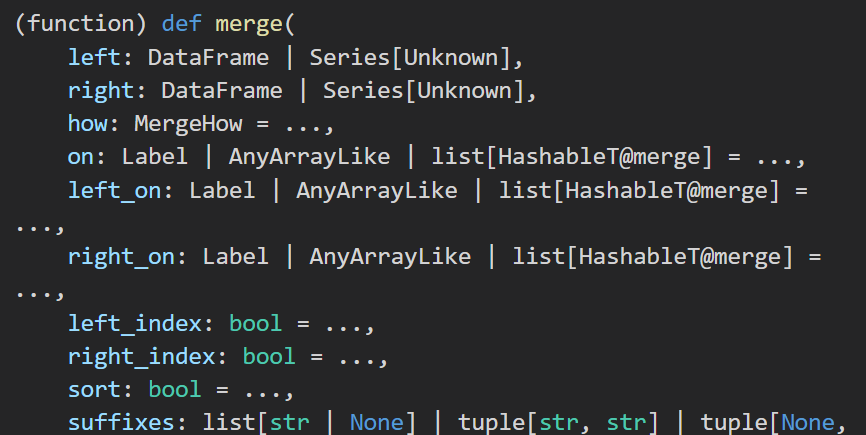
python">import pandas as pd
# 员工
signup = pd.read_csv('signup.csv')
# 项目
items = pd.read_csv('items.csv')
# 合并数据
data = pd.merge(items, signup, on='item_id', how='inner')
cnt = data.groupby(by='item_name')['item_name'].count()
print(cnt)DA38 统计运动会项目报名人数(二)

python">import pandas as pd
signup = pd.read_csv('signup.csv')
items = pd.read_csv('items.csv')
# 合并
data = pd.merge(items, signup, on='item_id', how='left')
cnt = data.groupby(by='item_name')['employee_id'].count()
#
print(cnt)DA39 多报名表的运动项目人数统计

python">import pandas as pd
signup = pd.read_csv("signup.csv")
signup1 = pd.read_csv("signup1.csv")
items = pd.read_csv("items.csv")
# 级联员工表
signup2 = pd.concat([signup, signup1], axis=0)
# 合并
data = pd.merge(items, signup2, on="item_id", how="inner")
cnt = data.groupby(by="item_name")["item_name"].count()
print(cnt)DA40 统计职能部分运动会某项目的报名信息

python">import pandas as pd
items = pd.read_csv("items.csv")
signup = pd.read_csv("signup.csv")
# 合并
data = pd.merge(items, signup)
result = (
data.query("item_name == 'javelin'&department == 'functional'")
.loc[:, ["employee_id", "name", "sex"]]
.reset_index(drop=True)
)
# reset_index是重置索引,原来的索引默认作为数据列保留,若不想要保留则设置参数 drop = True
print(result)
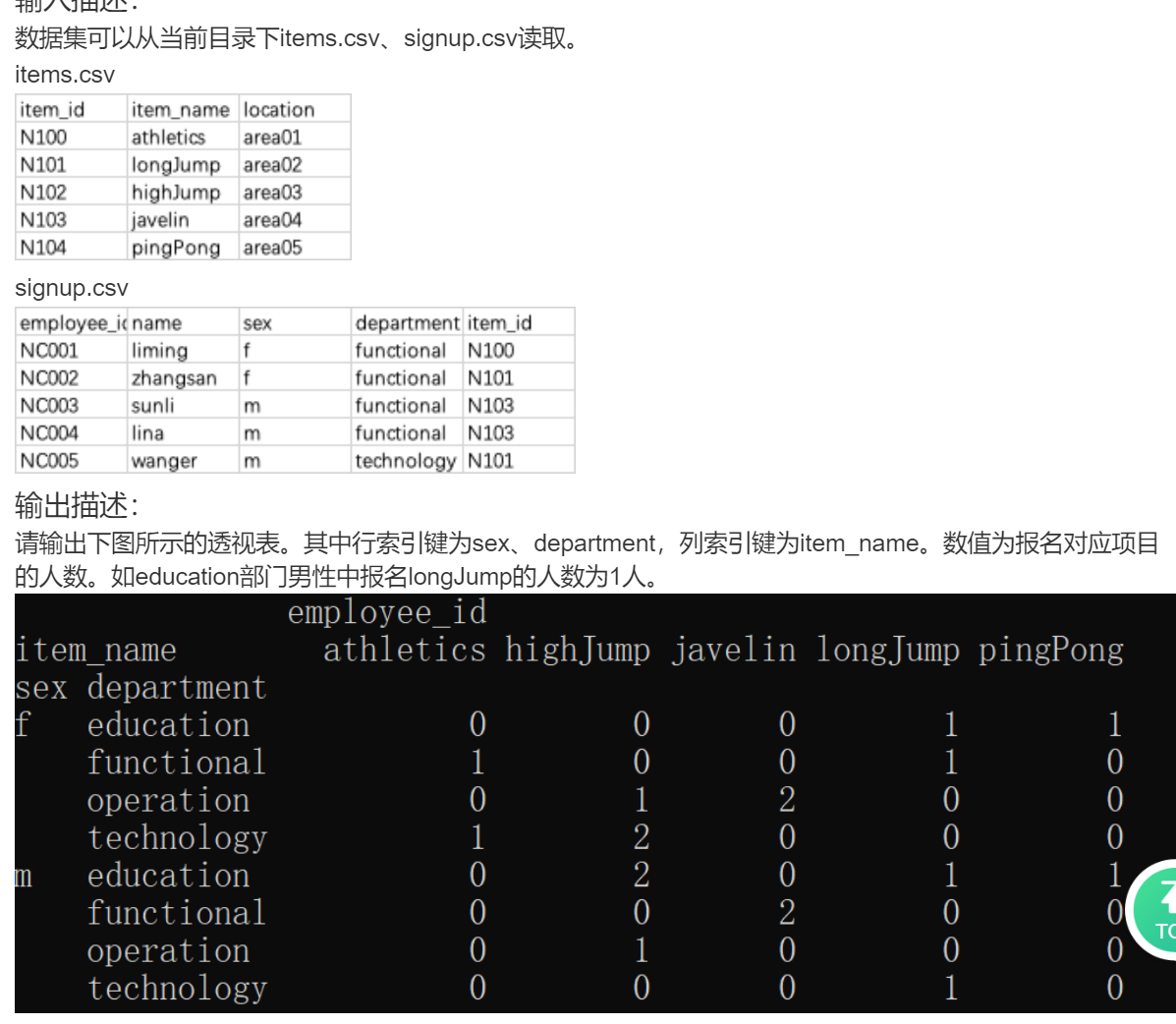
DA41 运动会各项目报名透视表
请你输出报名的各个项目情况(不包含没人报名的项目)对应的透视表。
python">import pandas as pd
signup = pd.read_csv("signup.csv")
items = pd.read_csv("items.csv")
data = pd.merge(signup, items, on="item_id", how="inner")
data1 = data.pivot_table(index=["sex", "department"],
columns="item_name",
aggfunc={'employee_id':'size'},
fill_value=0)
print(data1)
DA42 合并用户信息表与用户活跃表
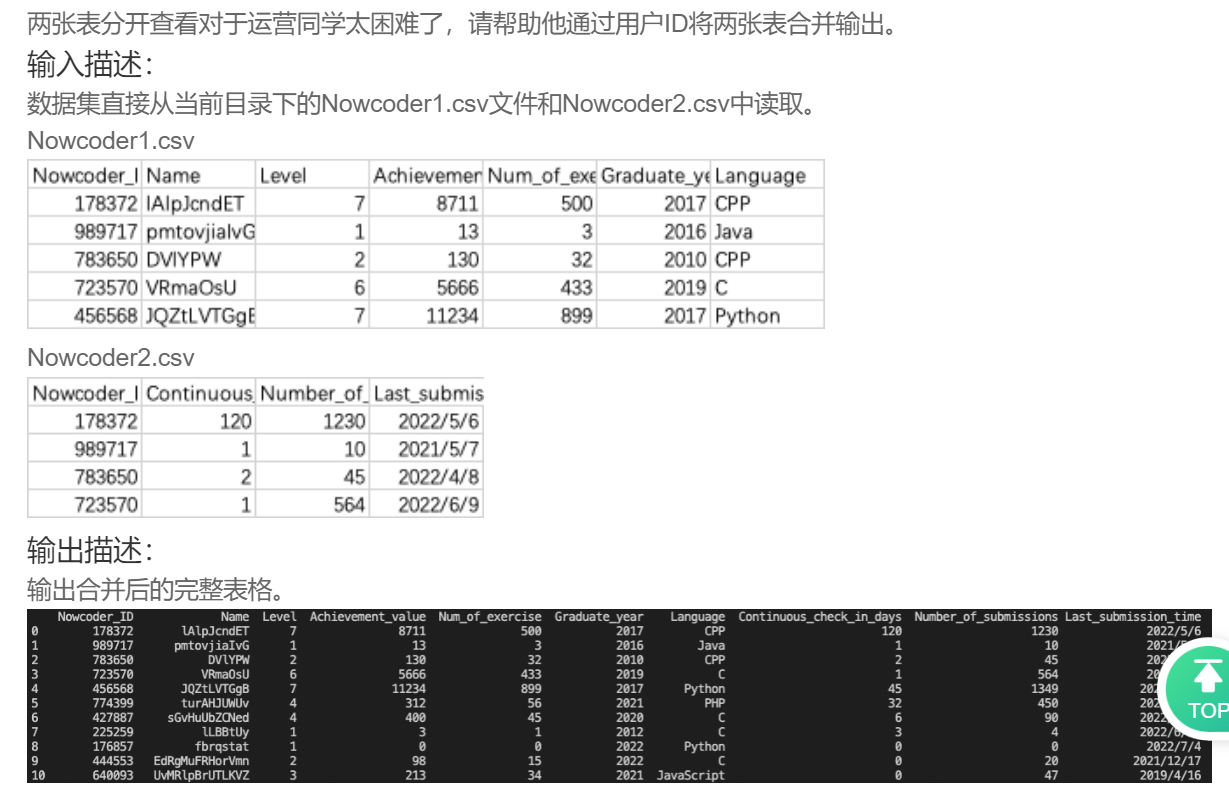
python">import pandas as pd
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
Nowcoder1 = pd.read_csv('Nowcoder1.csv', sep=',')
Nowcoder2 = pd.read_csv('Nowcoder2.csv', sep=',')
print(pd.merge(Nowcoder1,Nowcoder2,on='Nowcoder_ID'))
DA43 两份用户信息表格中的查找

python">import pandas as pd
N1 = pd.read_csv('Nowcoder1.csv')
N2 = pd.read_csv('Nowcoder2.csv')
#设置显示最大行、列和宽度
pd.set_option('display.width',300)
pd.set_option('display.max_rows',None)
pd.set_option('display.max_columns',None)
#合并
data = pd.merge(N1,N2,how = 'outer')
result = data.loc[:,['Name','Num_of_exercise','Number_of_submissions']]
print(result)九、排序
DA44 某店铺消费最多的前三名用户
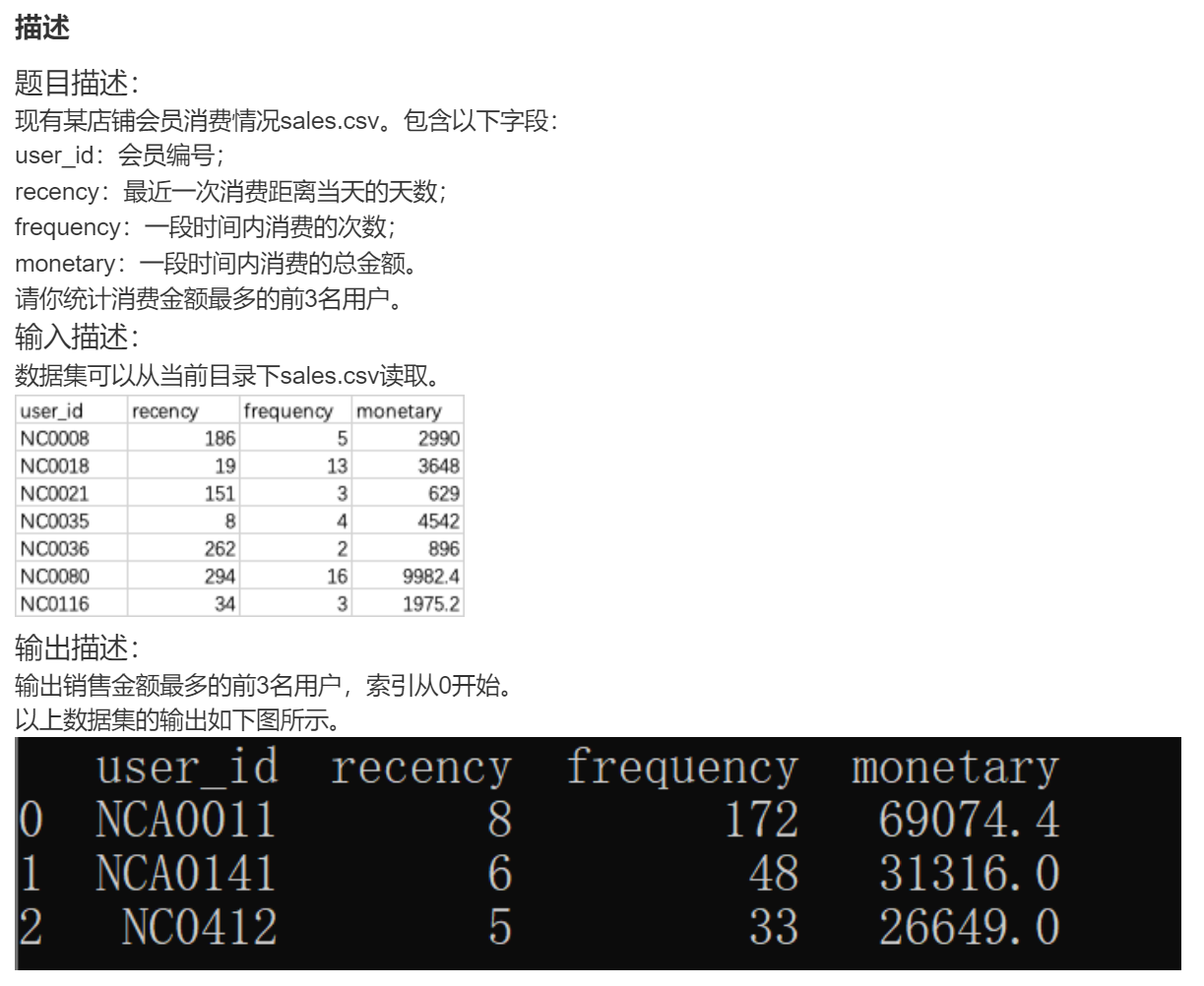
python">import pandas as pd
sales = pd.read_csv('sales.csv')
data = sales.sort_values(by='monetary', ascending=False).reset_index(drop=True)[:3]
print(data)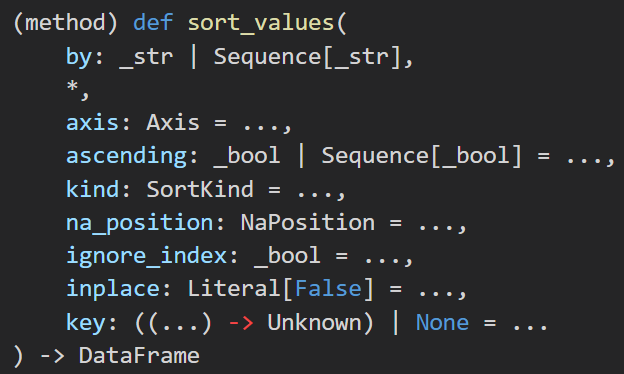
DA45 按照等级递增序查看牛客网用户信息
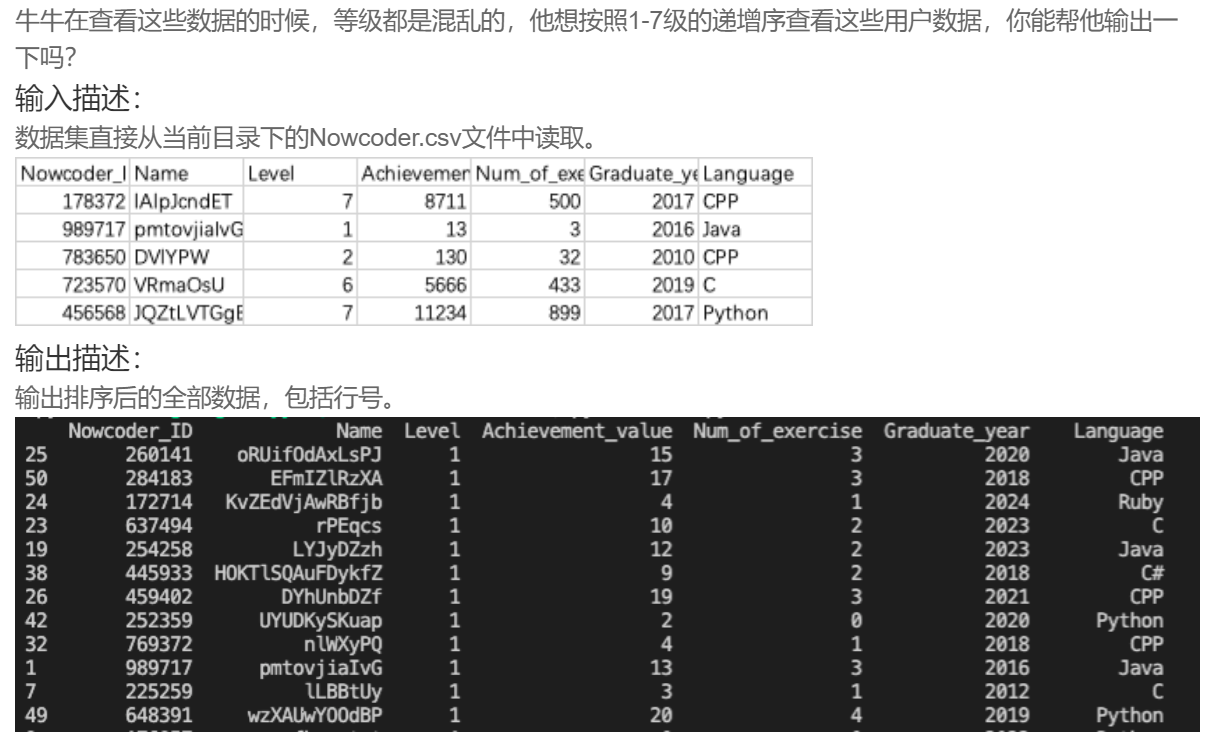
python">import pandas as pd
pd.set_option('display.width', 300) # 设置字符显示宽度
pd.set_option('display.max_rows', None) # 设置显示最大行
pd.set_option('display.max_columns', None)
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
df = Nowcoder.sort_values(by='Level',ascending=True)
print(df)十、函数
DA46 某店铺用户消费特征评分
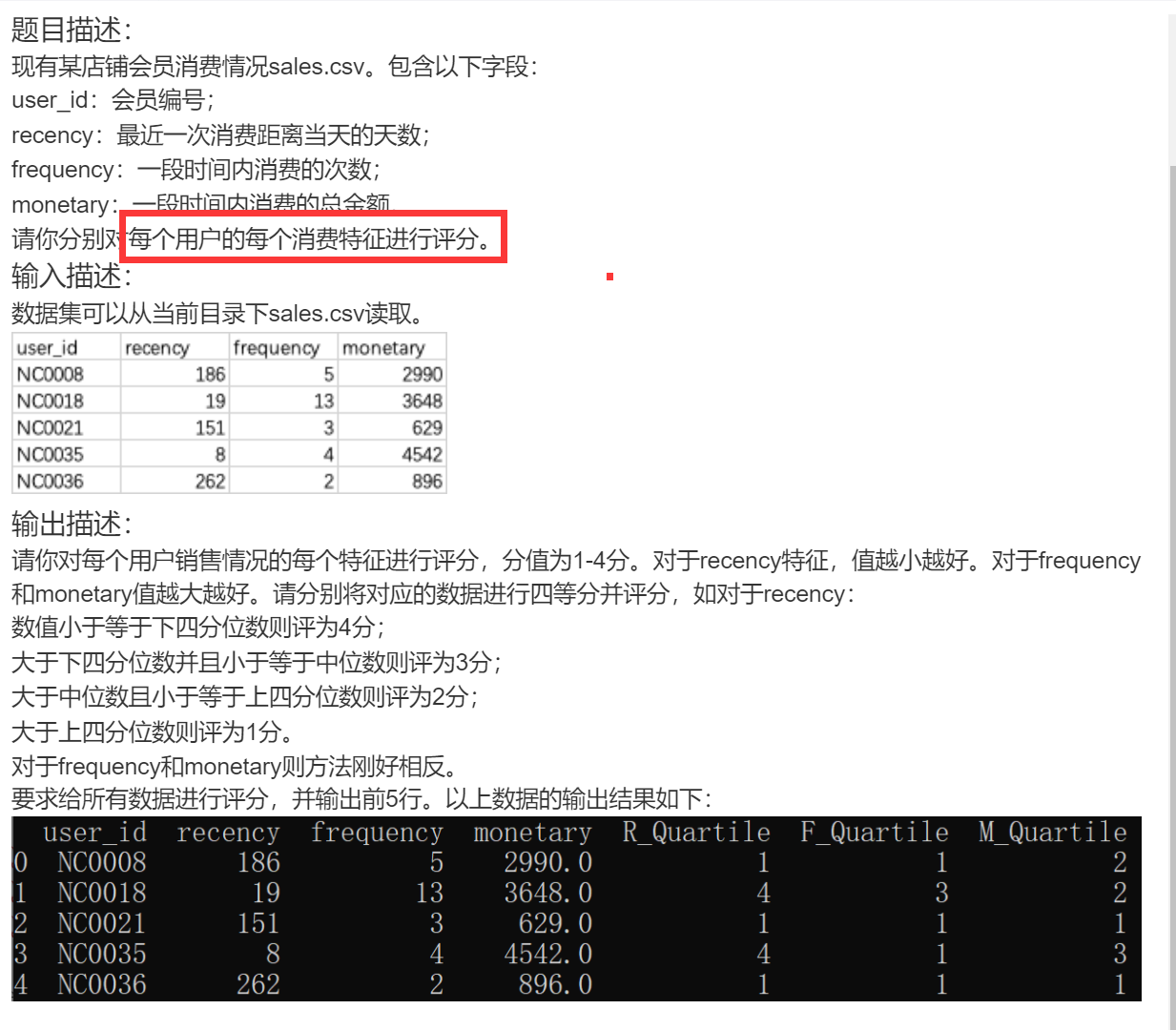
python">import pandas as pd
sales = pd.read_csv('sales.csv')
# 按照结果要求转换类型
sales[['monetary']] = sales[['monetary']].astype('float32')
# 求百分位
des = sales[['recency', 'frequency', 'monetary']].describe().loc['25%':'75%']
# 计算RFM
sales['R_Quartile'] = sales['recency'].apply(lambda x: 4 if x <= des.iloc[0,0] else (3 if x <= des.iloc[1,0] else (2 if x <= des.iloc[2,0] else 1)))
sales['F_Quartile'] = sales['frequency'].apply(lambda x: 1 if x <= des.iloc[0,1] else (2 if x <= des.iloc[1,1] else (3 if x <= des.iloc[2,1] else 4)))
sales['M_Quartile'] = sales['monetary'].apply(lambda x: 1 if x <= des.iloc[0,2] else (2 if x <= des.iloc[1,2] else (3 if x <= des.iloc[2,2] else 4)))
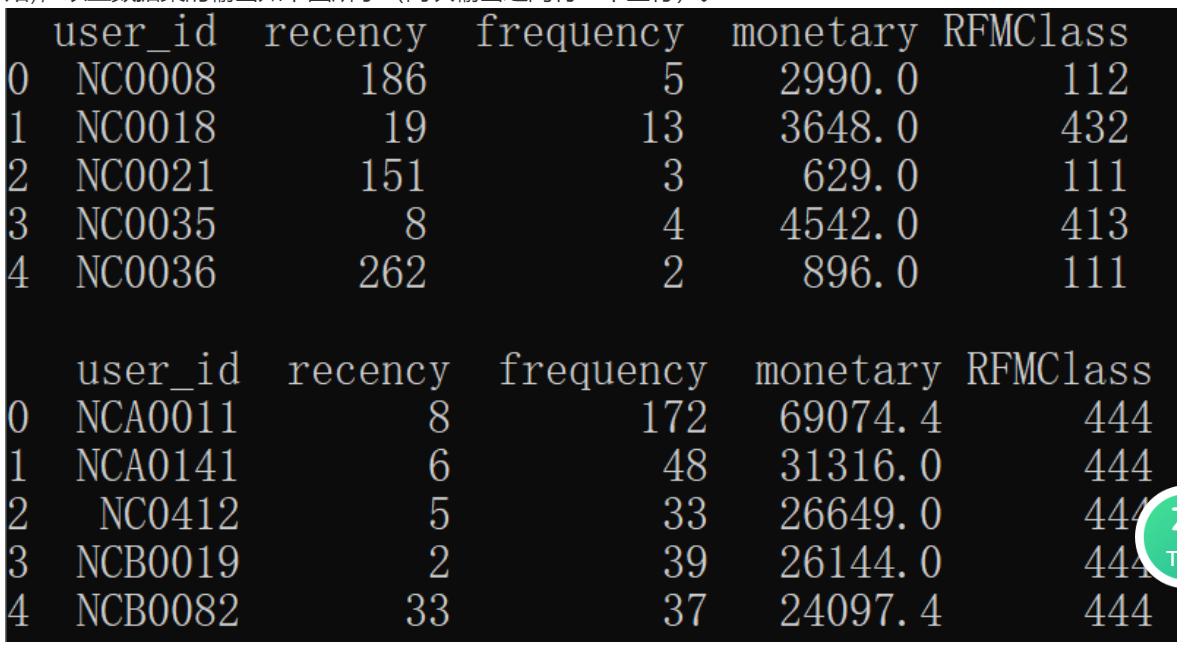
print(sales.head())DA47 筛选某店铺最有价值用户中消费最多前5名

python">import pandas as pd
sales = pd.read_csv("sales.csv")
# 按照结果要求转换类型
sales[["monetary"]] = sales[["monetary"]].astype("float32")
# 求百分位
des = sales[["recency", "frequency", "monetary"]].describe().loc["25%":"75%"]
# 计算RFM
R = (
sales["recency"]
.apply(
lambda x: 4
if x <= des.iloc[0, 0]
else (3 if x <= des.iloc[1, 0] else (2 if x <= des.iloc[2, 0] else 1))
)
.astype("str")
)
F = (
sales["frequency"]
.apply(
lambda x: 1
if x <= des.iloc[0, 1]
else (2 if x <= des.iloc[1, 1] else (3 if x <= des.iloc[2, 1] else 4))
)
.astype("str")
)
M = (
sales["monetary"]
.apply(
lambda x: 1
if x <= des.iloc[0, 2]
else (2 if x <= des.iloc[1, 2] else (3 if x <= des.iloc[2, 2] else 4))
)
.astype("str")
)
# 合并RFM
sales["RFMClass"] = R + F + M
#
print(sales.head())
# 筛选444用户
sales1 = (
sales[sales["RFMClass"] == "444"]
.sort_values(by="monetary", ascending=False)
.reset_index(drop=True)
)
#
print(sales1.head())