与你相识

博主介绍:
– 本人是普通大学生一枚,每天钻研计算机技能,CSDN主要分享一些技术内容,因我常常去寻找资料,不经常能找到合适的,精品的,全面的内容,导致我花费了大量的时间,所以会将摸索的内容全面细致记录下来。另外,我更多关于管理,生活的思考会在简书中发布,如果你想了解我对生活有哪些反思,探索,以及对管理或为人处世经验的总结,我也欢迎你来找我。
– 目前的学习专注于Go语言,辅学算法,前端领域。也会分享一些校内课程的学习,例如数据结构,计算机组成原理等等,如果你喜欢我的风格,请关注我,我们一起成长。
Table of Contents
- Elasticsearch
- elasticsearch在学习什么?
- 历史
- 什么是ELK
- 使用
- 安装
- Elasticsearch安装
- 安装可视化界面
- 解决elasticsearch和es-head之间的通信跨域问题
- Kibana安装
- 使用
- 汉化
- Es使用
- IK分词器
- 安装
- 使用
- REST风格
- 参考资料
- 总结
Elasticsearch
elasticsearch 读音:[ɪˈlæstɪk] [sɜːtʃ]
现在elasticsearch更新到7.x的版本了,它与6.x的差别很大,很多的api都不一样了,而官方针对6.x和7.x也有不同的文档表示。
elasticsearch_26">elasticsearch在学习什么?
我们在程序中往往需要用到查询功能,比如全文搜索,模糊搜索等,在传统的解决方案中,主要是使用SQL的like关键字来进行模糊查询,但是如果数据量太大了的话,这种方式的效率十分的慢。
当初的解决方案是给sql字段加上索引,但是这个虽然会把速度再提上一个档次,但是还是达不到一个大数据的要求。
这个时候我们就有必要去学习一下分布式搜索引擎了,elasticsearch就是做这个事情的,它就做一件事——搜索。
就拿下图来讲,如果我们要用SQL来做这面这些复杂的搜索,它的实现逻辑就会是否的复杂,而如果使用elasticsearch就会简单很多。
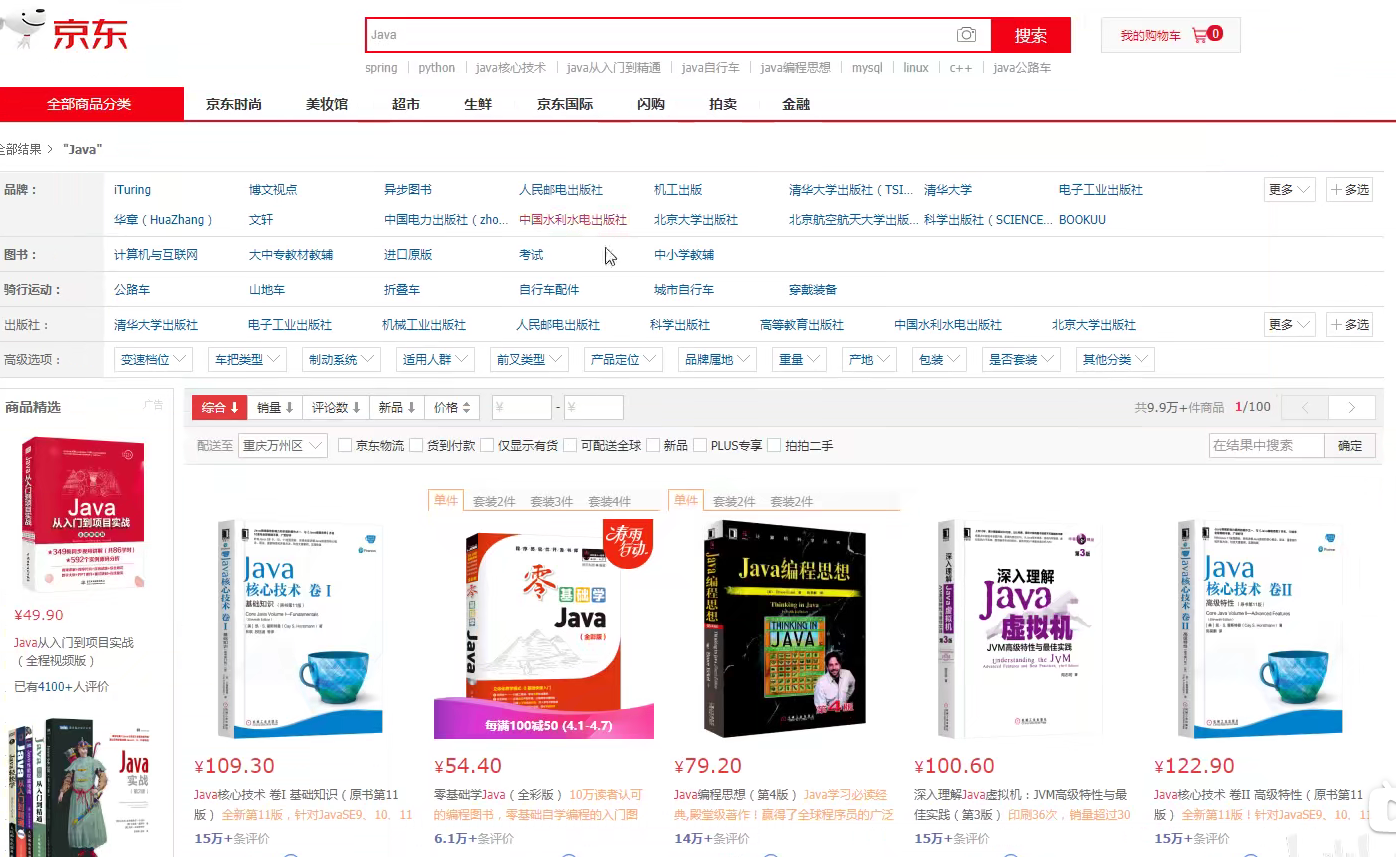
Elasticsearch是基于Lucene这个工具包做了一些封装和增强,它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
除了elasticsearch,Solr也可以干这件事情,所以我们在学习的过程中,也会对比和参考着进行学习。
建议在大数据了的情况下都使用ES来完成搜索功能。
历史
这个部分其实还有关于Lucene,Elasticsearch,Solr三者的介绍,以及ES和Solr的差别等。 但是我感觉用处不是很大,等我对它们各个使用的概念比较清晰的时候,再去了解这些背后的人文故事,可能更能感受其温度。
关于ES和Solr的选择:
截图一下视频中的片段,简单的了解一下。

什么是ELK
ELK是Elasticsearch、Logstash、Kibana三大开源框架的首字母大写简称。
Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架,它的搜索能力很强大,而Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式的数据,经过过滤之后再输出到不同目的地。 Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
它们三个合到一起常常被说是日志分析架构技术栈,但实际上ELK不仅仅适用于日志分析,还可以支持其它任何数据分析和收集的场景。
使用
今天我们在Windows环境下来试用一下,官方网站下载客户端工具巨慢,所以我们使用华为云的镜像下载。
-
ElasticSearch
-
logstash
-
kibana
安装
Elasticsearch安装
然后我们会下载下来三个压缩包,首先解压ElasticSearch。
熟悉目录:
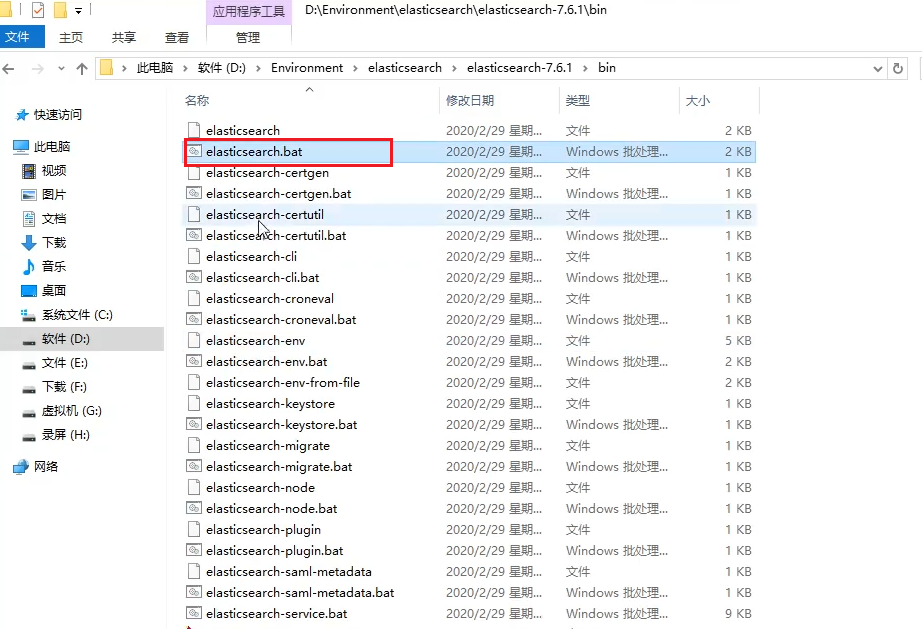
运行:
点击elasticsearch.bat文件运行。
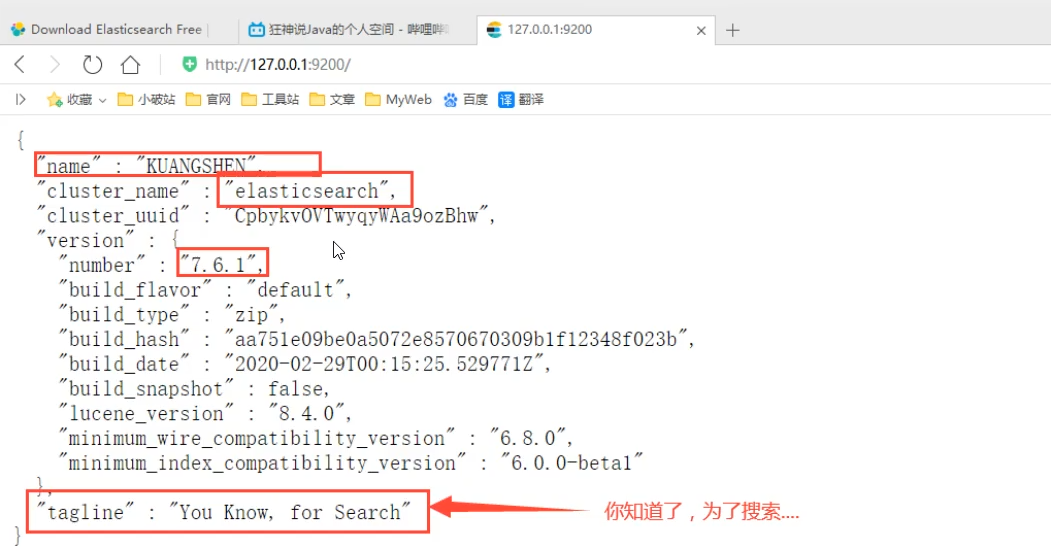
运行之后我们可以得知它的默认端口是9200,所以我们直接访问,进行访问测试。
安装可视化界面
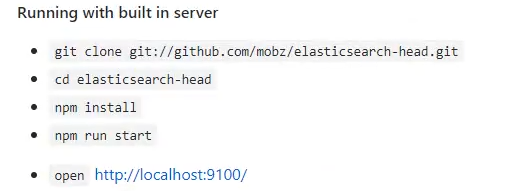
可视化界面有很多的插件,插件用的最多的是head插件,下载下来之后,可以通过github的read me文件来看elasticsearch-head如何启动。
elasticsearcheshead_98">解决elasticsearch和es-head之间的通信跨域问题
我们需要修改elasticsearch.yml文件,在最下面写上允许跨域的配置,然后重新启动一下elasticsearch即可。
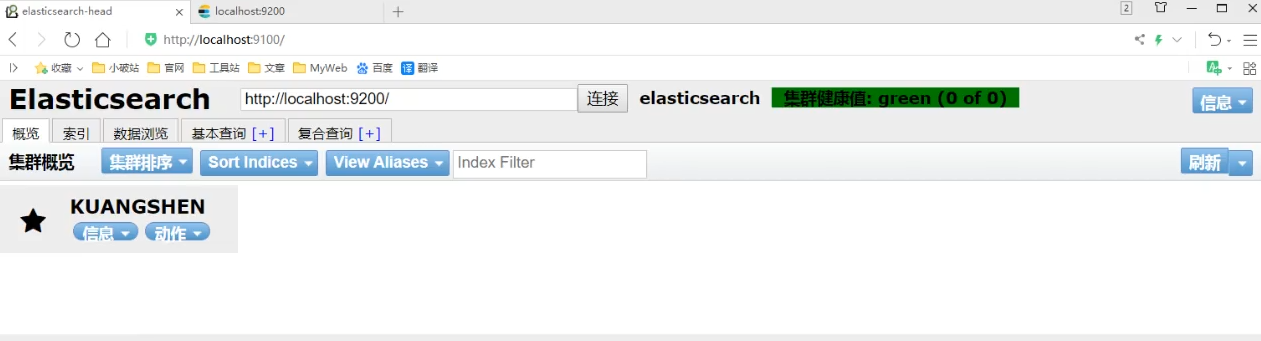
此时我们去es-head的图形化界面中,就会有下面这个样子。我们一般只关心前三个选项,概览就是所有的库信息,索引就是看有多少个索引库,所有的数据在数据浏览里。
后面的查询我们到Kibana中做。
Kibana安装
去Kibana官网进行安装即可。
使用
在bin目录下点击kibana.bat直接运行即可。可以发现其默认端口为5601,我们直接进入即可。
汉化
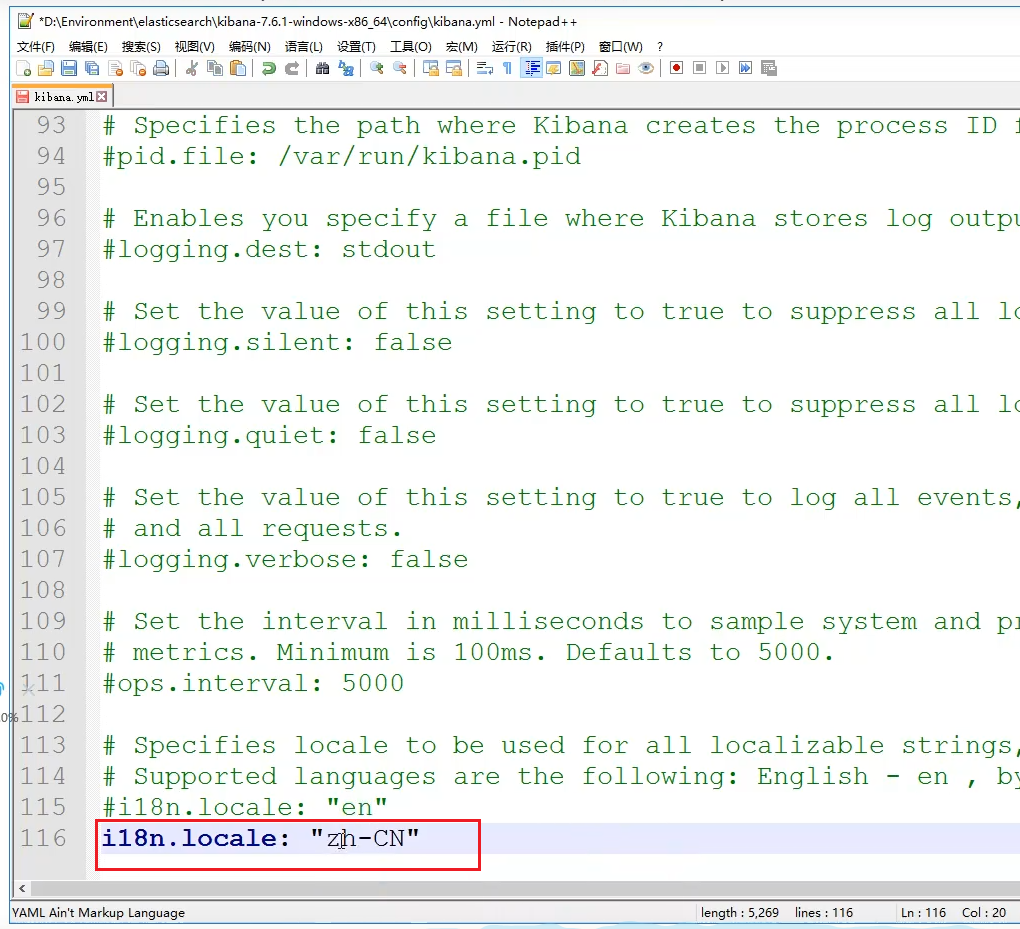
默认的测试页面是全英文的,我们需要对其进行汉化,Kibana本身已经支持了汉化,只是需要我们自己去配置文件中进行更改。我们找到其配置文件
可以看到它默认的是英文,我们在这里复制一行,改成中文即可。
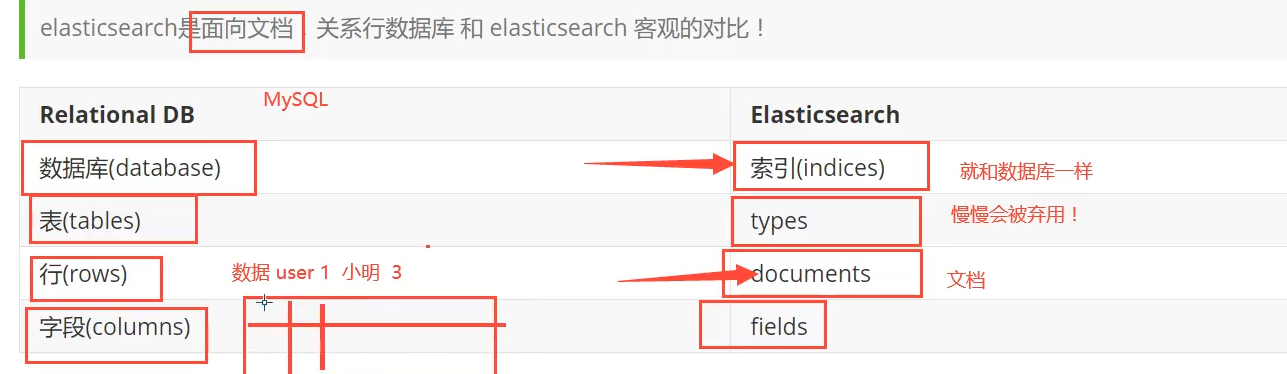
Es使用
types在8.0会被彻底取消。 了解即可。
IK分词器
它的作用是把一段信息划分为一个个的关键字,在搜索的时候就会把这个进行分词,也会把索引库中的数据进行分词,然后进行一个匹配的操作,默认的中文分词是把每一个字都看做一个词,比如“你好”,会分成“你”,“好”,这显然是有问题的,所以我们需要安装中文分词器ik来解决这个问题。
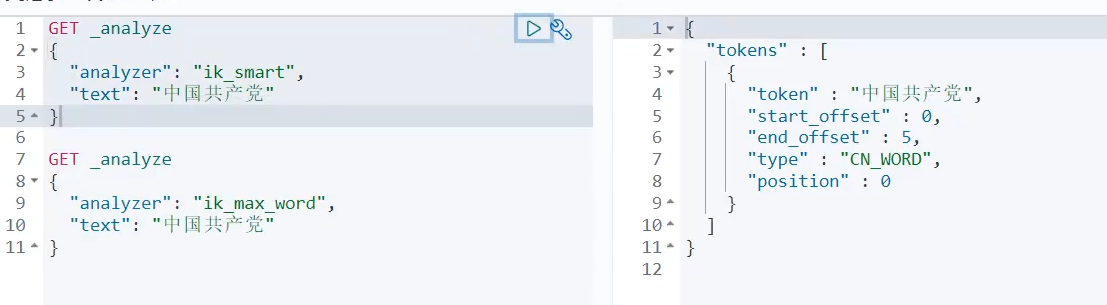
IK提供了两个分词算法:ik_smart和ik_max_word。 第一个为最少切分,第二个为最细粒度划分。
安装
我们只需要下载好IK分词器之后,解压到elasticsearch的plugins文件夹下,新建一个ik文件夹,然后放进去,重启elasticsearch就可以了,在elasticsearch重启的时候,可以看到ik plugins加载的过程。
也可以通过elasticsearch-plugin命令来查看elasticsearch安装的插件。
使用
ik_smart 是最少切分,它就是只切一次就可以了,原来是什么样子,现在还是什么样子。
ik_max_word是最细粒度划分,它就是穷尽的的信息的分词可能,原理是按照内部的一个字典来进行拆分的。
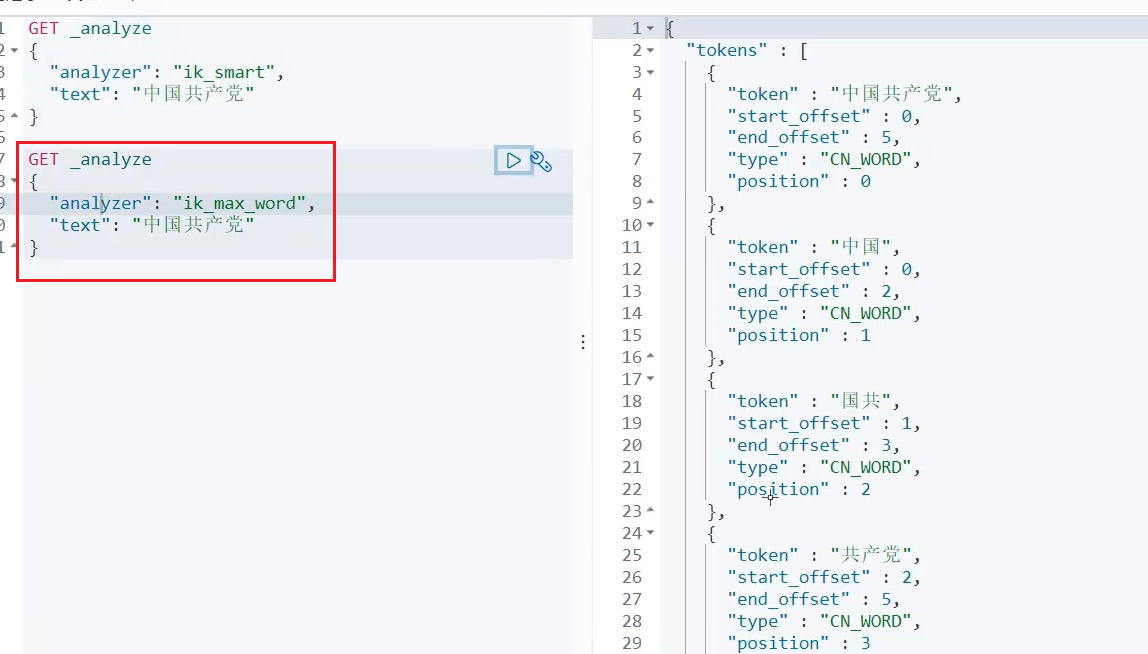
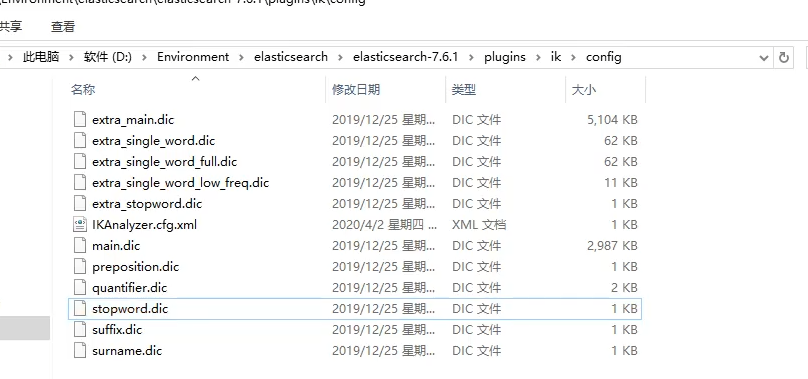
它会把它认为的词给拆分出来,拆分的方式是通过config文件下的各种dic文件,里面存了前缀后缀等字典文件,而这些默认的在有些时候是远远不足以我们的使用的,比如我想在网络上搜索我的名字——雅各布,但是它会给我拆分为“雅”,“各”,“布”,也就是对于IK分词器来说,它认为这三个字就是拆分开的,而我们想要把他们合到一起,我们就需要告诉IK分词器,这是一个词,这个时候就需要我们写一个自己的字典了。
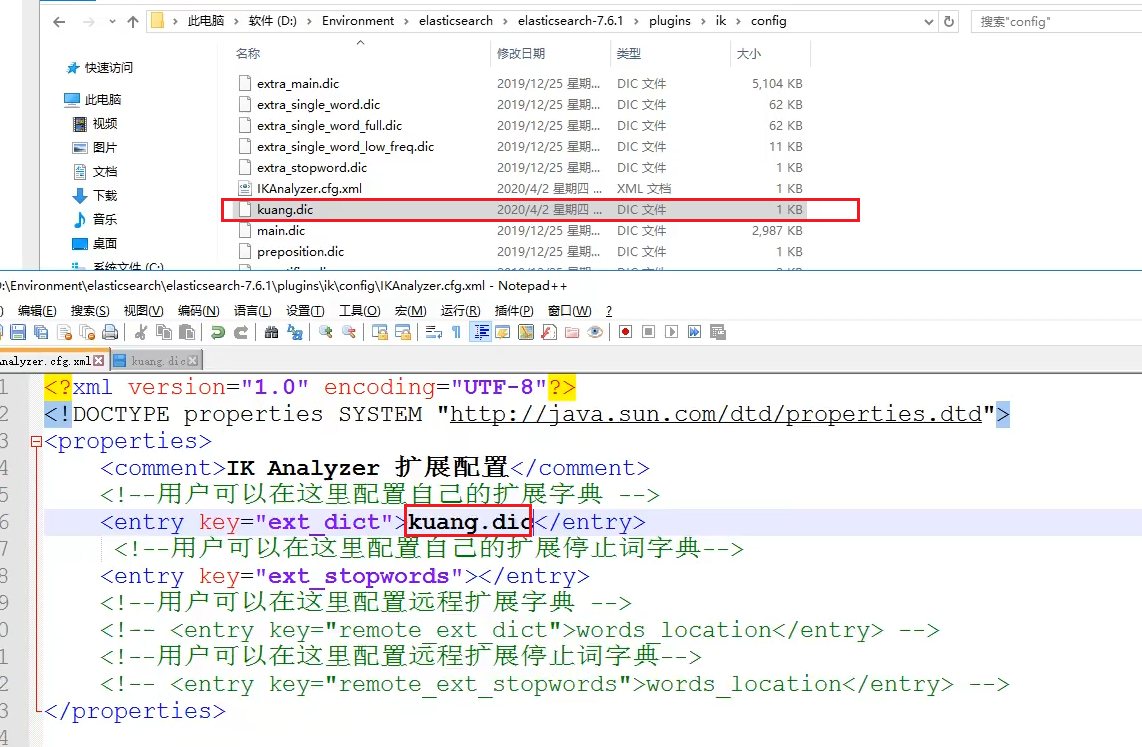
你可以创建自己的字典文件,比如里面写上了“雅各布”,这个时候ik就会认识“雅各布”这个词语了,保存之后,还需要在IK配置文件中配置一下用户的扩展字典的位置。
然后重启一下es即可。
REST风格
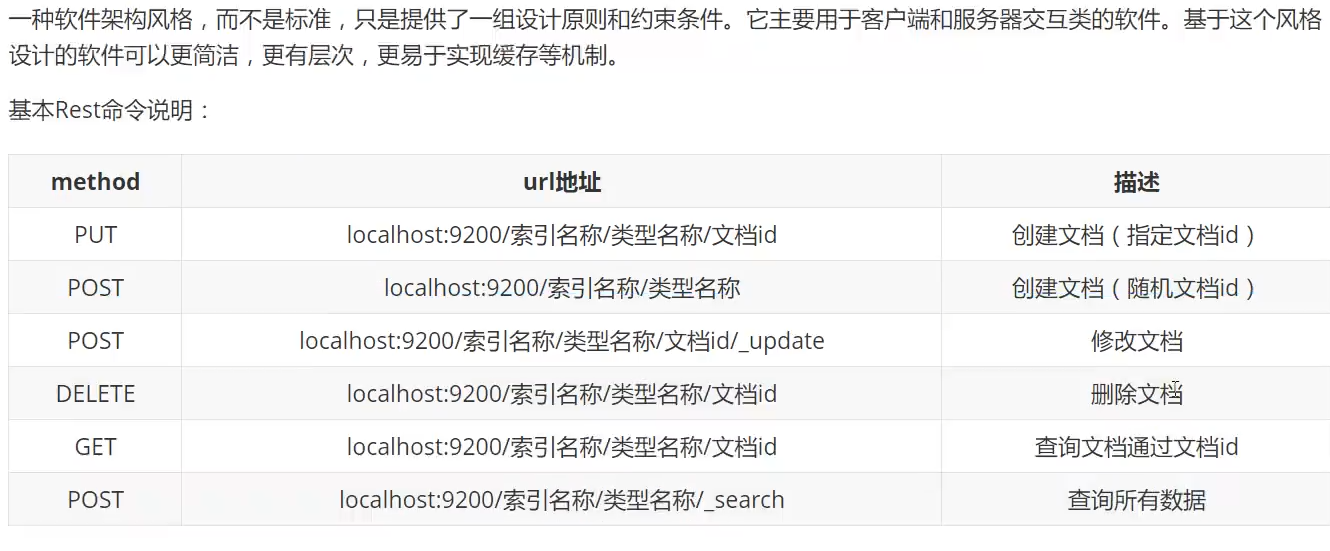
put用来创建一个索引,不仅是可以在这里发送请求,postman或者各种请求的工具都是可以发送请求来创建的。
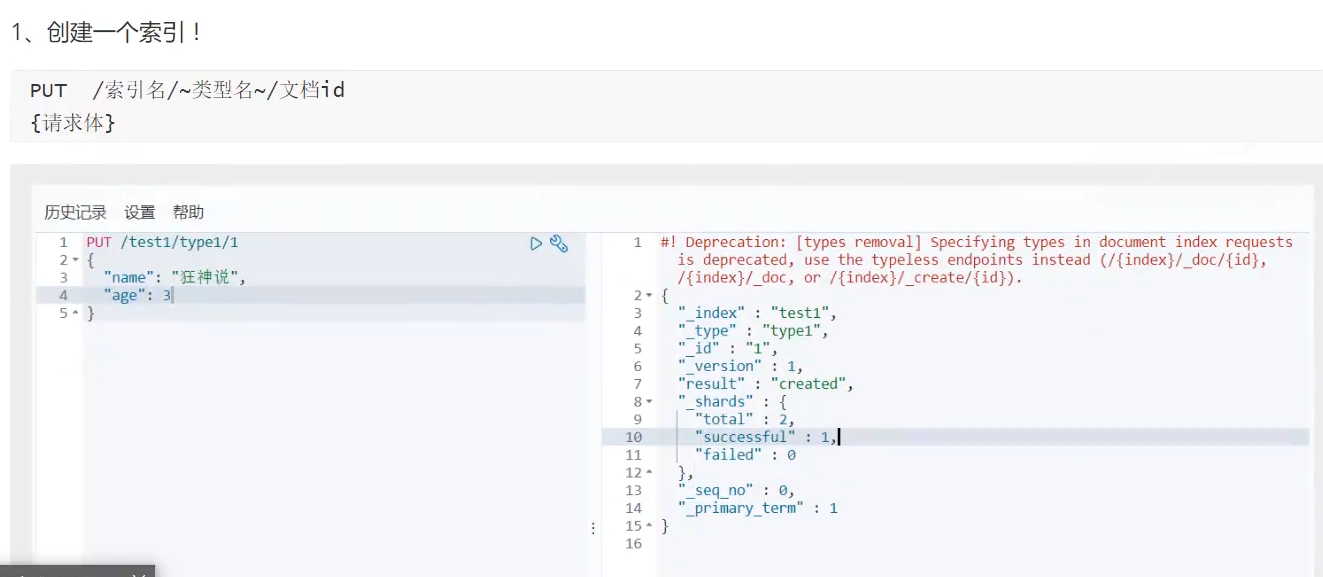
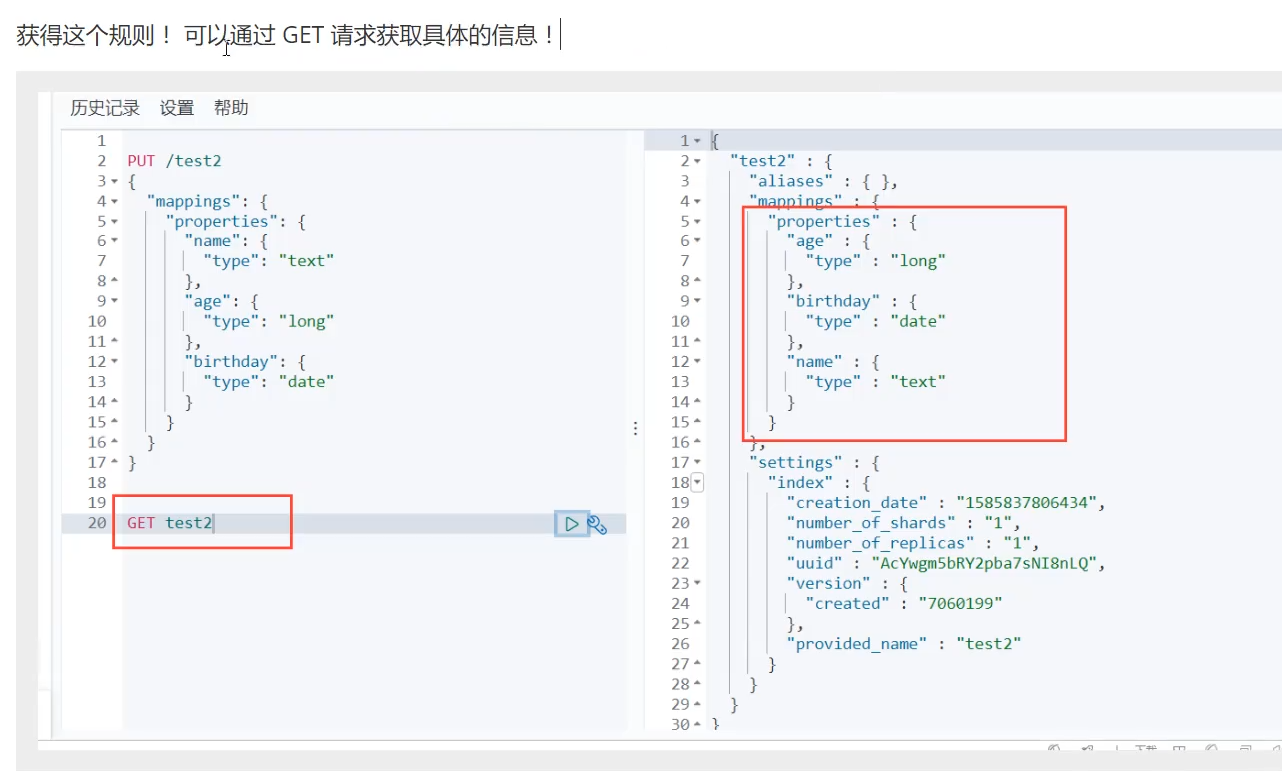
通过GET来获取具体索引的信息
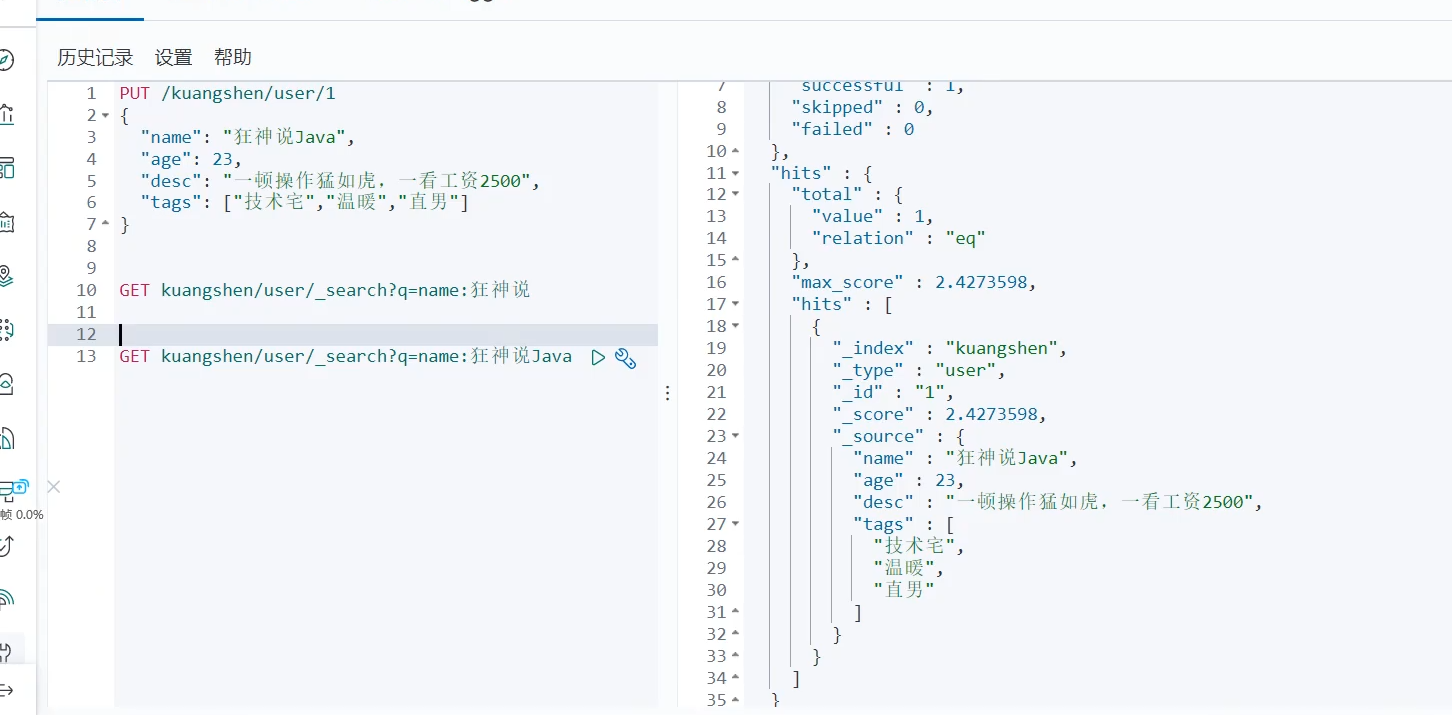
我们可以通过一些关键字来进行一些模糊匹配,以及右边的结果之中,_score表示了匹配度,version表示被修改的次数。
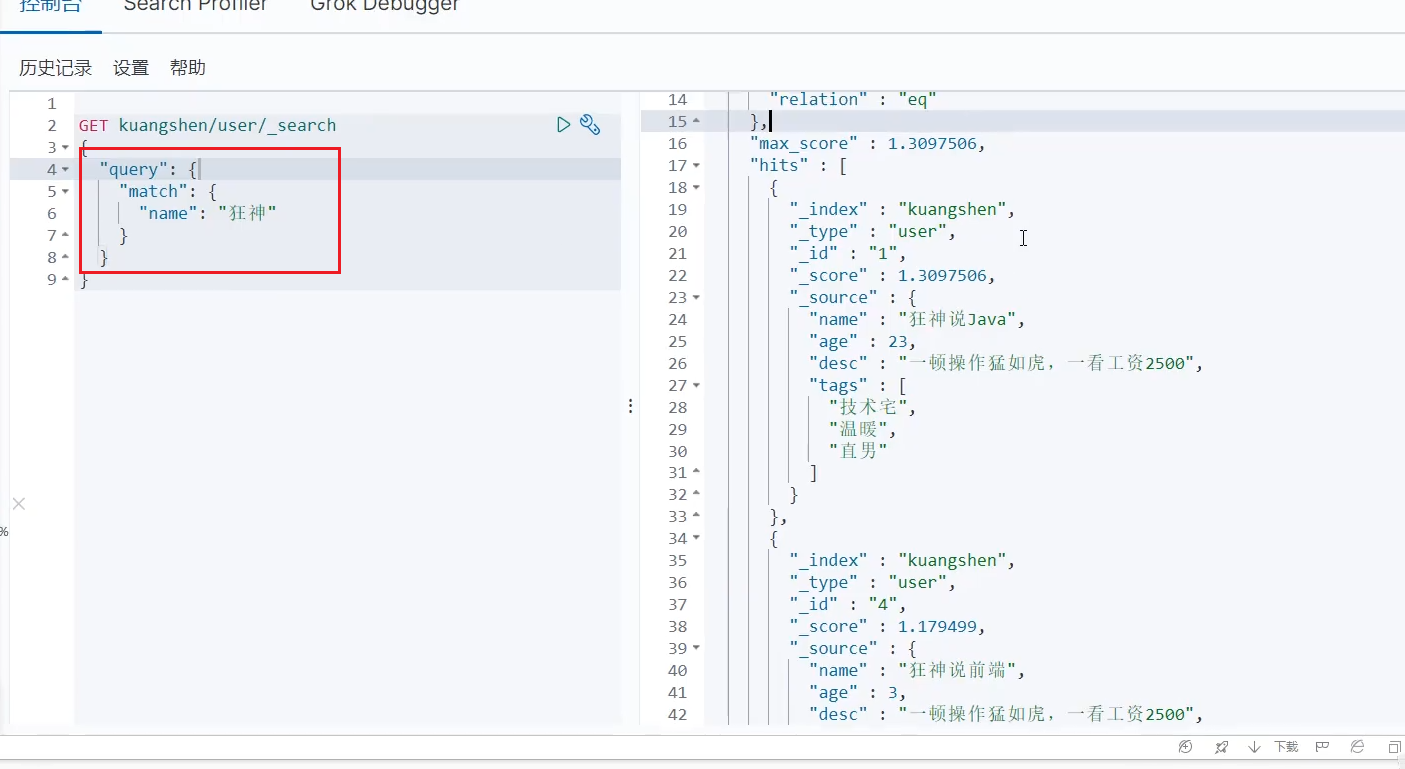
我们可以在get中使用各种参数和api来完成我们的需求,然后右边会根据score的权重来进行排序。
参考资料
- 狂神说 | bilibili视频
- 李文周 | 个人博客
总结
由于时间不太够,所以用四倍速过了一遍视频,目前脑子里只是知道ELK是干什么的,然后怎么安装和解压,以及一些使用方式。
等到以后如何用到es的时候,需要再去看一遍文档。
欢迎评论区讨论,或指出问题。 如果觉得写的不错,欢迎点赞,转发,收藏。



