来源:https://urlify.cn/ZnUrqm
列表
列表:用于存储任意数目、任意类型的数据集合。
列表的创建
1. 基本语法[]创建
a = [1, 'jack', True, 100]b = []2. list()创建
使用list()可以将任何可迭代的数据转化成列表
a = list() # 创建一个空列表b = list(range(5)) # [0, 1, 2, 3, 4]c = list('nice') # ['n', 'i', 'c', 'e']3. 通过range()创建整数列表
range()可以帮助我们非常方便的创建整数列表,这在开发中及其有用。语法格式为:range([start,]end[,step])
start参数:可选,表示起始数字。默认是0。
end参数:必选,表示结尾数字。
step参数:可选,表示步长,默认为1。
python3中range()返回的是一个range对象,而不是列表。我们需要通过list()方法将其转换成列表对象。
a = list(range(-3, 2, 1)) # [-3, -2, -1, 0, 1]b = list(range(2, -3, -1)) # [2, 1, 0, -1, -2] 4. 列表推导式
a = [i * 2 for i in range(5) if i % 2 == 0] # [0, 4, 8]points = [(x, y) for x in range(0, 2) for y in range(1, 3)]print(points) # [(0, 1), (0, 2), (1, 1), (1, 2)]列表元素的增加
当列表增加和删除元素时,列表会自动进行内存管理,大大减少了程序员的负担。但这个特点涉及列表元素的大量移动,效率较低。除非必要,我们一般只在列表的尾部添加元素或删除元素,这会大大提高列表的操作效率。
append()
>>>a = [20,40]>>>a.append(80)>>>a[20,40,80]+运算符
并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中。这样,会涉及大量的复制操作,对于操作大量元素不建议使用。
>>> a = [3, 1, 4]>>> b = [4, 2]>>> a + b[3, 1, 4, 4, 2]extend()
将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象。
>>> a = [3, 2]>>> a.extend([4, 6])>>> a[3, 2, 4, 6]insert()
使用insert()方法可以将指定的元素插入到列表对象的任意指定位置。这样会让插入位置后面所有的元素进行移动,会影响处理速度。涉及大量元素时,尽量避免使用。类似发生这种移动的函数还有:remove()、pop()、del(),它们在删除非尾部元素时也会发生操作位置后面元素的移动。
>>> a = [2, 5, 8]>>> a.insert(1, 'jack')>>> a[2, 'jack', 5, 8]乘法
使用乘法扩展列表,生成一个新列表,新列表元素时原列表元素的多次重复。
>>> a = [4, 5]>>> a * 3[4, 5, 4, 5, 4, 5]适用于乘法操作的,还有:字符串、元组。
列表元素的删除
del()
删除列表指定位置的元素。
>>> a = [2, 3, 5, 7, 8]>>> del a[1]>>> a[2, 5, 7, 8]pop()
删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素。
>>> a = [3, 6, 7, 8, 2]>>> b = a.pop()>>> b2>>> c = a.pop(1)>>> c6remove()
删除首次出现的指定元素,若不存在该元素抛出异常。
>>> a=[10,20,30,40,50,20,30,20,30]>>> a.remove(20)>>> a[10, 30, 40, 50, 20, 30, 20, 30]clear()
清空一个列表。
a = [3, 6, 7, 8, 2]a.clear()print(a) # []列表元素的访问
通过索引直接访问元素
>>> a = [2, 4, 6]>>> a[1]4index()获得指定元素在列表中首次出现的索引
index()可以获取指定元素首次出现的索引位置。语法是:index(value,[start,[end]])。其中,start和end指定了搜索的范围。
>>> a = [10, 20, 30, 40, 50, 20, 30, 20, 30]>>> a.index(20)1>>> a.index(20, 3)5>>> a.index(20, 6, 8)7列表元素出现的次数
返回指定元素在列表中出现的次数。
>>> a = [10, 20, 30, 40, 50, 20, 30, 20, 30]>>> a.count(20)3切片(slice)
[起始偏移量start:终止偏移量end[:步长step]]
三个量为正数的情况下
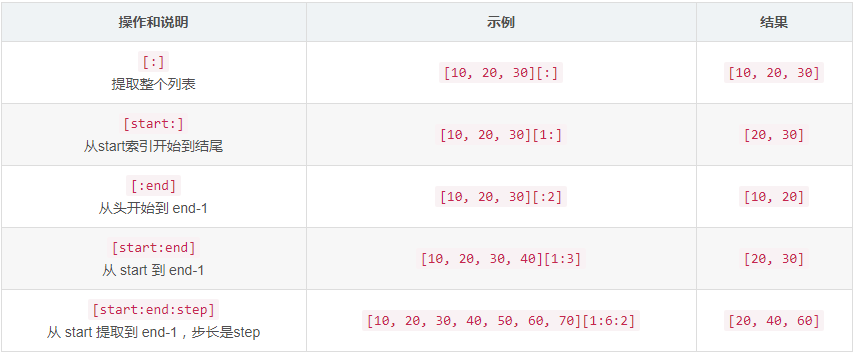
三个量为负数的情况

t1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]print(t1[100:]) # []print(t1[0:-1]) # [11, 22, 33, 44, 55, 66, 77, 88]print(t1[1:5:-1]) # []print(t1[-1:-5:-1]) # [99, 88, 77, 66]print(t1[-5:-1:-1]) # []print(t1[5:-1:-1]) # []print(t1[::-1]) # [99, 88, 77, 66, 55, 44, 33, 22, 11]# 注意以下两个print(t1[3::-1]) # [44, 33, 22, 11]print(t1[3::1]) # [44, 55, 66, 77, 88, 99]列表的排序
修改原列表,不创建新列表的排序
a = [3, 2, 8, 4, 6]print(id(a)) # 2180873605704a.sort() # 默认升序print(a) # [2, 3, 4, 6, 8]print(id(a)) # 2180873605704a.sort(reverse=True)print(a) # [8, 6, 4, 3, 2]# 将序列的所有元素随机排序import randomb = [3, 2, 8, 4, 6]random.shuffle(b)print(b) # [4, 3, 6, 2, 8]创建新列表的排序
通过内置函数sorted()进行排序,这个方法返回新列表,不对原列表做修改。
a = [3, 2, 8, 4, 6]b = sorted(a) # 默认升序c = sorted(a, reverse=True) # 降序print(b) # [2, 3, 4, 6, 8]print(c) # [8, 6, 4, 3, 2]冒泡排序
list1 = [34,54,6,5,65,100,4,19,50,3]#冒泡排序,以升序为例#外层循环:控制比较的轮数for i in range(len(list1) - 1): #内层循环:控制每一轮比较的次数,兼顾参与比较的下标 for j in range(len(list1) - 1 - i): #比较:只要符合条件则交换位置, # 如果下标小的元素 > 下标大的元素,则交换位置 if list1[j] < list1[j + 1]: list1[j],list1[j + 1] = list1[j + 1],list1[j]print(list1)选择排序
li = [17, 4, 77, 2, 32, 56, 23]# 外层循环:控制比较的轮数for i in range(len(li) - 1): # 内层循环:控制每一轮比较的次数 for j in range(i + 1, len(li)): # 如果下标小的元素>下标大的元素,则交换位置 if li[i] > li[j]: li[i], li[j] = li[j], li[i]print(li)列表元素的查找
顺序查找
# 顺序查找# 1.需求:查找指定元素在列表中的位置list1 = [5, 6, 5, 6, 24, 17, 56, 4]key = 6for i in range(len(list1)): if key == list1[i]: print("%d在列表中的位置为:%d" % (key,i))# 2.需求:模拟系统的index功能,只需要查找元素在列表中第一次出现的下标,如果查找不到,打印not found# 列表.index(元素),返回指定元素在列表中第一次出现的下标list1 = [5, 6, 5, 6, 24, 17, 56, 4]key = 10for i in range(len(list1)): if key == list1[i]: print("%d在列表中的位置为:%d" % (key,i)) breakelse: print("not found")# 3.需求:查找一个数字列表中的最大值以及对应的下标num_list = [34, 6, 546, 5, 100, 16, 77]max_value = num_list[0]max_index = 0for i in range(1, len(num_list)): if num_list[i] > max_value: max_value = num_list[i] max_index = iprint("最大值%d在列表中的位置为:%d" % (max_value,max_index))# 4.需求:查找一个数字列表中的第二大值以及对应的下标num_list = [34, 6, 546, 5, 100, 546, 546, 16, 77]# 备份new_list = num_list.copy()# 升序排序for i in range(len(new_list) - 1): for j in range(len(new_list) - 1 - i): if new_list[j] > new_list[j + 1]: new_list[j],new_list[j + 1] = new_list[j + 1],new_list[j]print(new_list)# 获取最大值max_value = new_list[-1]# 统计最大值的个数max_count = new_list.count(max_value)# 获取第二大值second_value = new_list[-(max_count + 1)]# 查找在列表中的位置:顺序查找for i in range(len(num_list)): if second_value == num_list[i]: print("第二大值%d在列表中的下表为:%d" % (second_value,i))二分法查找
# 二分法查找的前提:有序li = [45, 65, 7, 67, 100, 5, 3, 2, 35]# 升序new_li = sorted(li)key = 100# 定义变量,表示索引的最小值和最大值left = 0right = len(new_li) - 1# left和right会一直改变# 在改变过程中,直到left==rightwhile left <= right: # 计算中间下标 middle = (left + right) // 2 # 比较 if new_li[middle] < key: # 重置left的值 left = middle + 1 elif new_li[middle] > key: # 重置right的值 right = middle - 1 else: print(f'key的索引为{li.index(new_li[middle])}') breakelse: print('查找的key不存在')列表的其他方法
reverse()
用于列表中数据的逆序排列。
a = [3, 2, 8, 4, 6]a.reverse()print(a) # [6, 4, 8, 2, 3]copy()
复制列表,属于浅拷贝。
a = [3, 6, 7, 8, 2]b = a.copy()print(b) # [3, 6, 7, 8, 2]列表相关的内置函数
max()和min()
返回列表中的最大值和最小值
a = [3, 2, 8, 4, 6]print(max(a)) # 8print(min(a)) # 2sum()
对数值型列表的所有元素进行求和操作,对非数值型列表运算则会报错。
a = [3, 2, 8, 4, 6]print(sum(a)) # 23如果本文对你有帮助,点个“在看”呗!
-END-